

Data Machina #200
Data Machina #200
LLMs Coronation. StarCoder. GPTutor. CodeGen2. Prompt Injection Explained. The Math of Neural Nets. Pandas AI. SuperGradients. JSONFormer. Auto-ML GPT. Unlimiformer. Auto EdA & DataViz.
The Coronation of LLMs. My friend -who enjoys coding in OCaml and Prolog- says that LLMs are of no use to him. I contra-argue: that’s because nobody in this world would train an LLM on such obscure languages LOL! For now, The LLM has been anointed by the AI/ML community as the new king; crown and magic powers included. Let me be less ceremonial, and share with you 6 trends happening in LLM-landia:
New, Powerful LLMs for Coding, AI-Pair programming
StarCoder: A State-of-the-Art LLM for Code. StarCoder is a 5B LLM with 8k context, 1 Trillion tokens, trained on 80+ programming languages. StarCoderBase outperforms existing open Code LLMs on popular programming benchmarks and matches or surpasses closed models like early versions of Codex/Copilot.
CodeGen2: Lessons for Training LLMs on Programming and Natural Languages. A team @SalesforceResearch has come up with a new approach to making the training of LLMs for coding and program synthesis more efficient. The key idea for the model architecture, is to unify encoder and decoder-based models into a single prefix-LM.
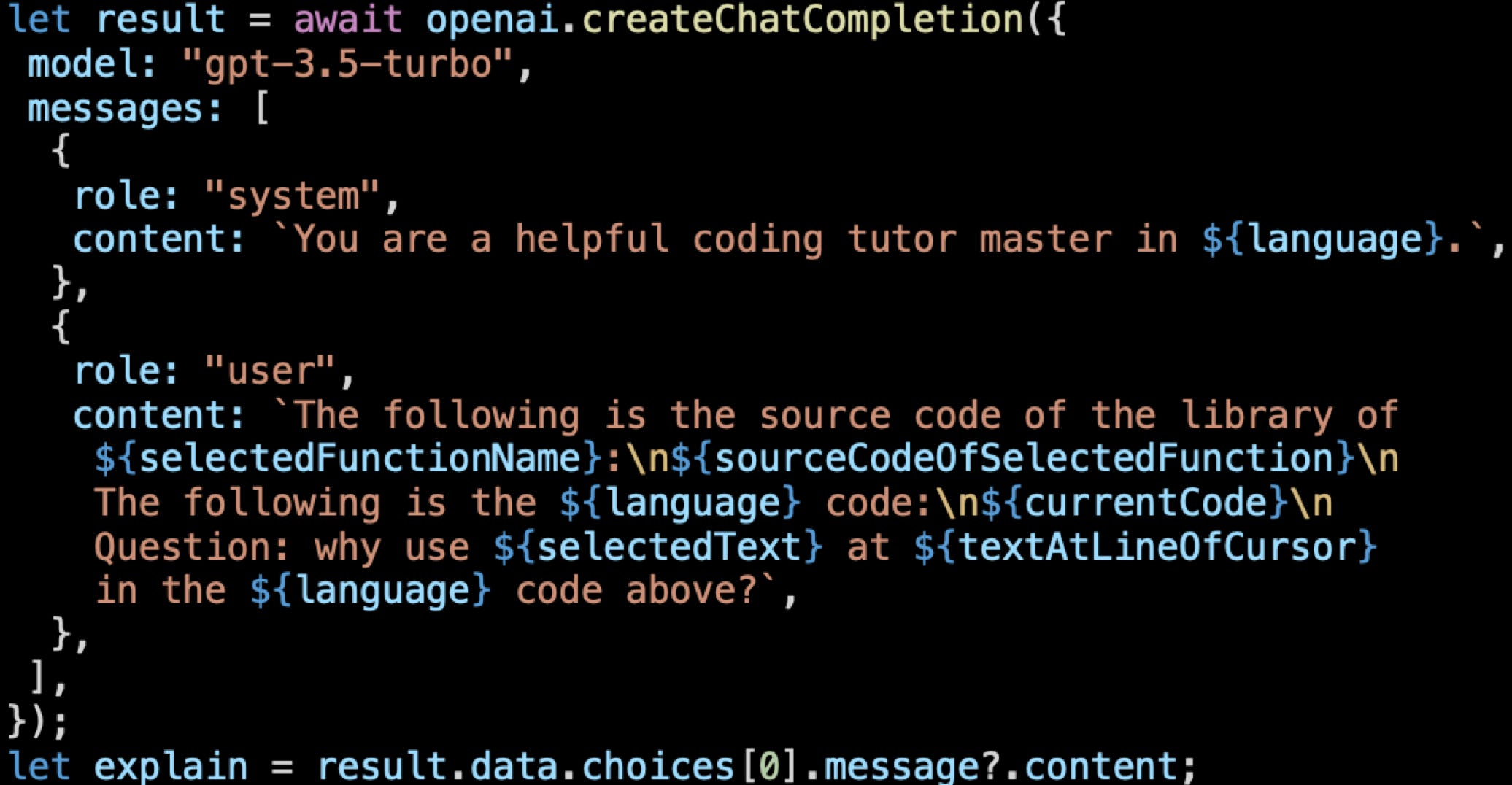
GPTutor: A ChatGPT-powered programming tool, which is a Visual Studio Code extension, that uses the ChatGPT API to provide programming code explanations. The researchers claim that GPTutor delivers the most concise and accurate explanations compared to vanilla ChatGPT and GitHub Copilot
Easier training of LLMs
Autotrain, a no-code tool for training SoTA models for NLP, CV, Speech or Tabular tasks. For those who don’t want to spend time on the technical details of training a model. Autotrain will enable non-technical users to train LLMs.
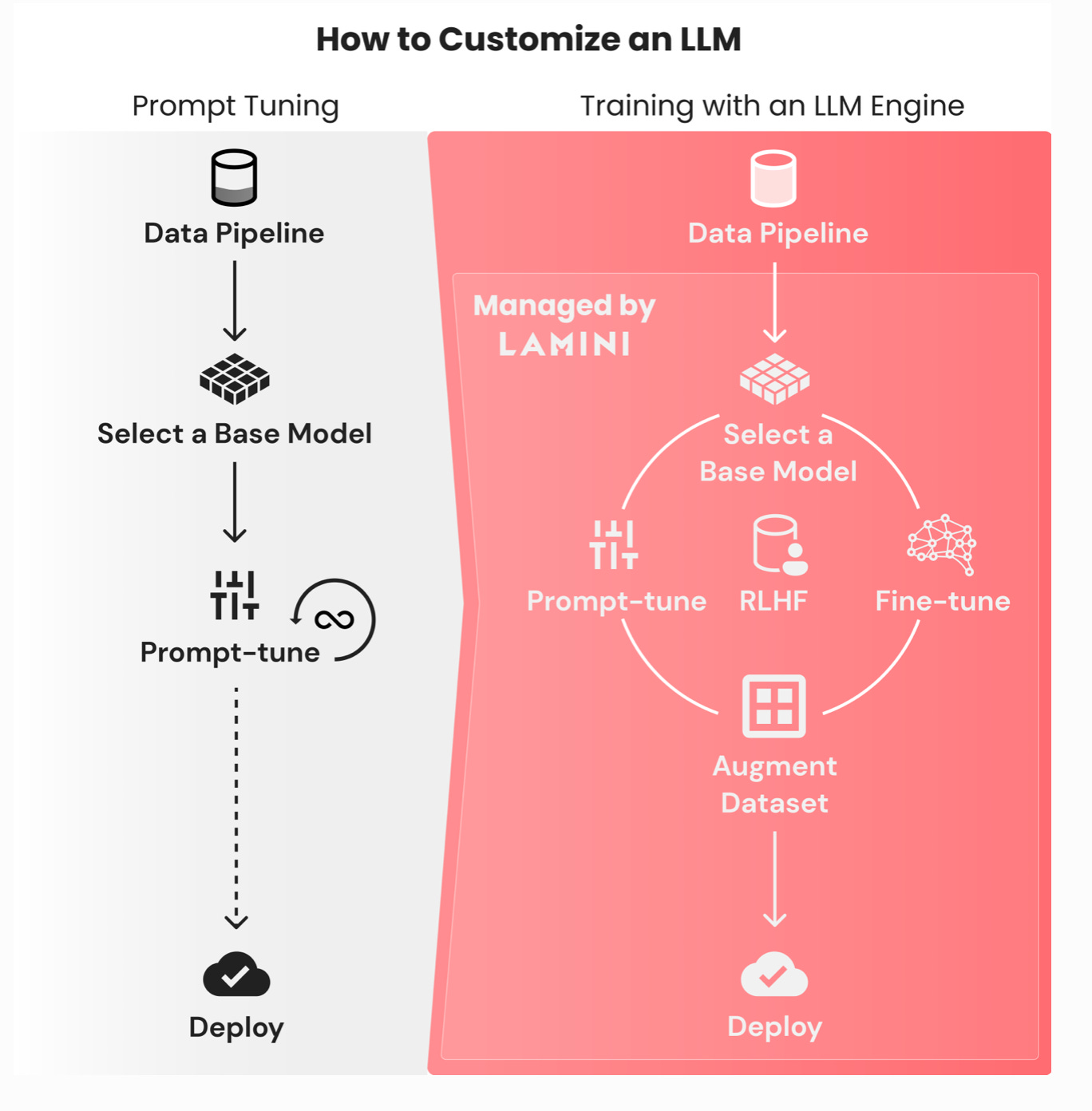
Lamini: Training LLMs should be as easy as prompt-tuning an LLM. Lamini is an engine that allows any developer, not just machine learning experts, to train high-performing LLMs, as good as ChatGPT, on large datasets with just a few lines of code
Smaller, More Powerful LLMs
GPT-JT-6B-v1: a new model that uses a decentralized training algorithm, fine-tuned GPT-J (6B) on 3.53 billion tokens. Th researchers claim that GPT-JT significantly improves the performance of classification tasks over the original GPT-J, and even outperforms most 100B+ parameter models!
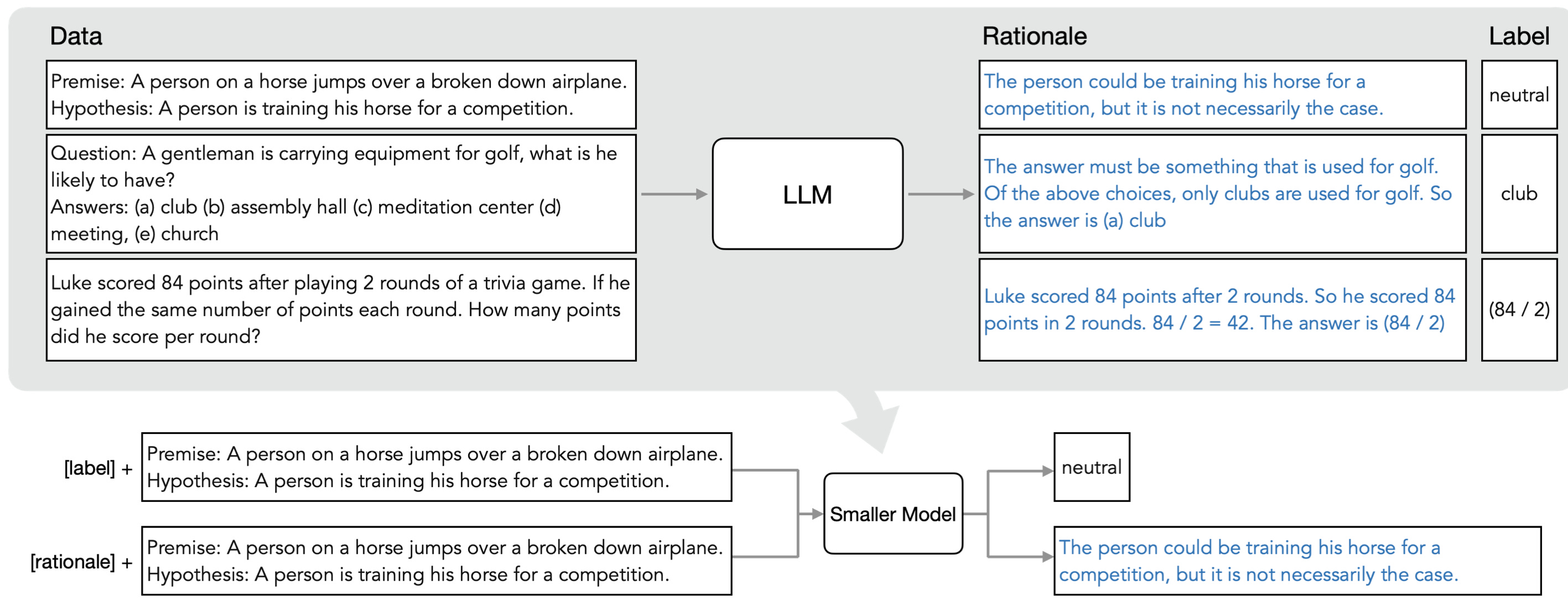
Distilling Step-by-Step! A new method that (a) trains smaller models that outperform LLMs, and (b) achieves so by leveraging less training data needed by fine-tuning or distillation. The researchers claim that their 770M T5 model outperforms the 540B PaLM model using only 80% of available data on a benchmark task.
Easier, Faster LLMOps
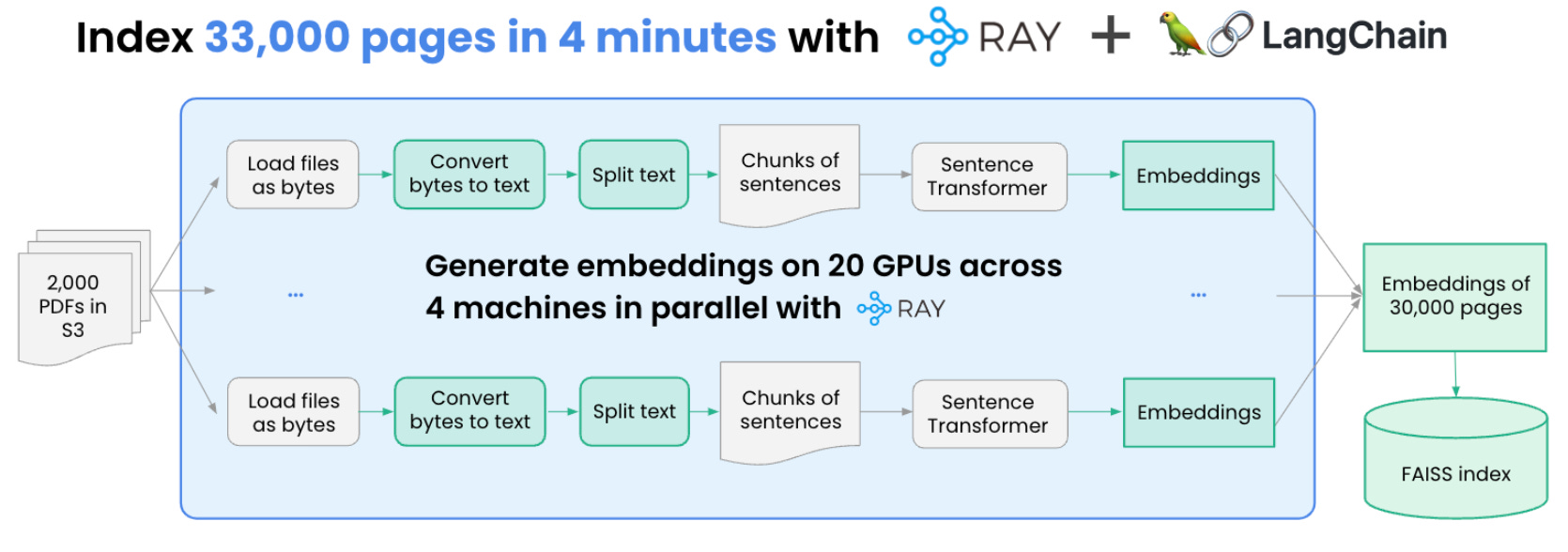
Turbocharge LangChain NOW: A guide to 20x faster embedding. In this blog post, Amog & Philippe at Anyscale, show an example on how to speed up and scale document embeddings at a cheaper cost, using Ray Data, PyPDF, LangChain, and a FAISS vector store.
Re-implementing LangChain in 100 lines of code LangChain is one of the most popular tools for augmenting and extending LLMs. But some engineers are complaining that LangChain is a bit complex and time consuming, sometimes producing poor results. Is there a better way to improve LangChain?
New, Commercially Usable LLMs
MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs. MPT-7B is a transformer trained from scratch on 1T tokens of text and codeYou can train, fine-tune, and deploy your own private MPT models, either starting from one of Mosaic’s checkpoints or training from scratch.
New AI Programming Languages
Mojo: A new programming language for all AI developers. Mojo combines the usability of Python with the performance of C, unlocking unparalleled programmability of AI hardware and extensibility of AI models. Checkout Jeremy’s demo here.
It’s 2023, and the ancient tradition of anointing and crowning a king still mesmerises millions of people. I know quite a few people that would be rather mesmerised by transformer puzzles.
Have a nice week.
10 Link-o-Troned
the ML Pythonista
the ML codeR
Deep & Other Learning Bits
AI/ DL ResearchDocs
Unlimiformer: Long-Range Transformers with Unlimited Length Input
Causal Reasoning and LLMs: Opening a New Frontier for Causality
El Robótico
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
As always, a wealth of information in your email.