

Data Machina #201
Data Machina #201
Small or Large LMs? PaLM 2. Claude 100K-t. Lit-Parrot. MLC LLM. LLM Tune. Transformer Agents. Plan & Execute Agents. Constitutional AI. Compressing Models. AttentionViz. LLM Bootcamp. privateGPT.
Small or Large? The LMs Divergence. The AI Giants keep releasing bigger, more powerful, often closed LMs. In parallel, I feel like the AI/ML community is pulling ahead by releasing, simpler, tinier LMs, that are super-efficient at delivering good enough results at a much cheaper cost than LLMs. Checkout the new Open LLM Leaderboard. Is it time to drop the L in Large Language Models? Let’s see…
The new Google PaLM 2 model. They claim it achieves SoTA at reasoning, coding, and multilingual tasks. PaLM will power 25 Google products. Read more on What PaLM 2 can do and How PaLM 2 was built and evaluated
We’ve learned through our research that it’s not as simple as “bigger is better,” and that research creativity is key to building great models. Zoubin Ghahramani, Vice President, Google DeepMind
Interestingly, PaLM 2 will be made available in 4 sizes from the little Gecko to the huge Unicorn version. It seems like Enrico a.k.a conceptofmind has been busy… He just released an open-source implementation of Google PaLM models.
Bigger context window token size. Anthropic announced a huge increase in Claude’s context window up to 100K tokens. See: Introducing 100K Context Windows. Some ppl say that this kind of context window size would reduce the need for vector search DBs and improve summarisation, knowledge extraction, CoT and knowledge synthesis. But…
Testing Claude’s 100k-token window. Jerry @LLamaIndex reviews Claude’s 100K-token model, and summarises what Claude does and doesn’t do well. Jerry says that one of the issues is -obviously- cost; Claude is expensive. Another issue apparently is poor “reasoning” when using the create-and-refine prompt in LLaMA Index.
Agents dealing with much bigger prompt sizes, more complex prompts. Until recently, the team at LangChain has been following the ReAct Pattern. But now -to address the issue of bigger prompt sizes and the more complex prompts- LangChain just released Plan and Execute Agents. It looks like LangChain’s architecture is getting quite big.

New Transformer Agents to integrate with 100K+ models. This is quite huge. Basically, Transformer Agents is a natural language API on top of transformers, that enables you to leverage 100,000+ Hugging Face models in all modalities: text, images, video, audio, docs… Thomas posted a great summary on all the Transformer Agents features.
Optimising LLM Model Training and Inference. Optimisation techniques have been at the core of ML forever. But I guess LLMs have exacerbated the need for newer or better advanced techniques to optimise model training and inference. Two great reads below:
Make Your ML Models Smaller, Faster and Less Data-Hungry. This post is a nice summary of methods for reducing model size, training with less memory, reusing existing models, and efficiently using small datasets.

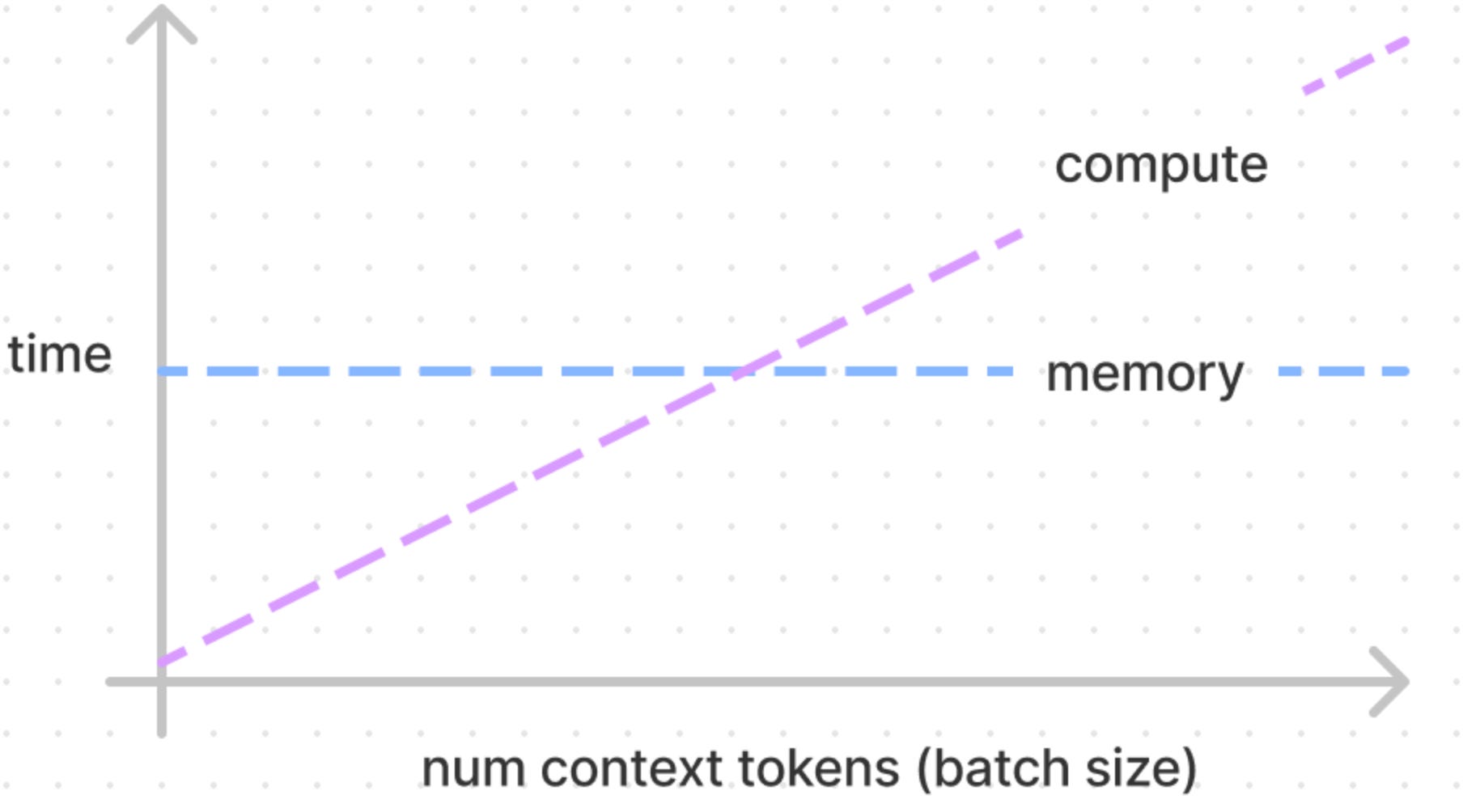
Transformer Inference Arithmetic A few-principles reasoning about LLM inference performance, with no experiments or difficult math. A very simple model of latency for inference turns out to be a good fit for emprical results.
On compression. The Information Theory bottleneck principle has been used to solve the trade-off between compression and relevant info. Self-Supervised Learning -somehow- came to the rescue with learning from data without explicit labels. However, the optimal information objective in SSL remains unclear. Yann Le Cun and Ravid Schwartz have written a new paper on all this:
To Compress or Not to Compress. A comprehensive review of the intersection between information theory, self-supervised learning, and deep neural networks.

More on small, efficient models that use techniques like quantisation, and adapters. Let me me tell you about these little two gems:
Lit-Parrot: An new implementation of SoTA open source language models. Based on Lit-LLaMA and nanoGPT models, you can run Lit-Parrot on consumer devices. Supports flash attention, LLaMA-Adapter, pre-training. Apache 2.0 license!
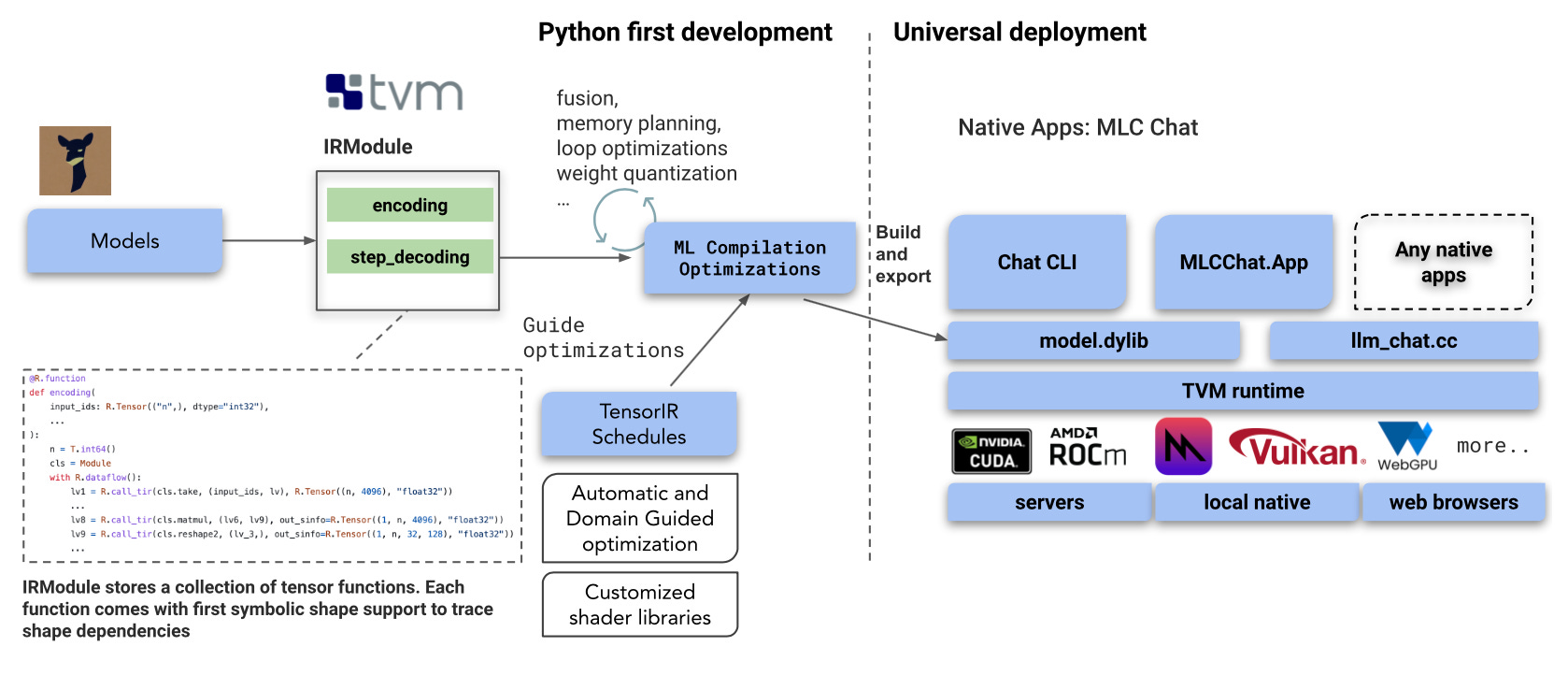
MLC LLM (updated repo, demo, blog)- MLC LLM is a universal solution that allows everyone to develop, optimise and deploy AI language models natively on any backend including consumer devices.
Have a nice week.
10 Link-o-Troned
AttentionViz: A Global Visualisation of Transformer Attention
[lecture] LeCun: On Machines that Can Understand, Reason, & Plan
the ML Pythonista
the ML codeR
Deep & Other Learning Bits
AI/ DL ResearchDocs
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.