

Data Machina #203
Data Machina #203
Finetuning FTW! QLoRA paper. Guanaco model. LIMA paper. GORILLA model. Falcon 40B model. Finetuning Redpajama. LM Studio. Scikit LLM.
Finetuning is All You Need? Model finetuning in combination with some efficient computational techniques is unleashing a whole new level of performance in small LLMs. Adding to that, the permissively commercial licenses of some of the small LLMs, is really enabling the democratisation of LLMs. Let me share with you some of my notes on the latest in finetuning:
The QLoRA paper: A new, super efficient approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance…Read more here: QLoRA: Efficient Finetuning of Quantized LLMs. QLoRA uses bitsandbytes for quantization and is integrated with PEFT (SoTA Parameter-Efficient Fine-Tuning) and transformers libraries.

The new fine-tuned Guanaco 33B hits 99.3% of ChatGPT performance. Using QLoRA, Guanaco outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of ChatGPT performance while only requiring 24 hours of finetuning on a single GPU! Access the live demo here, checkout this notebook. Or compare Guanaco vs ChatGPT model responses here.
Learn more about QLoRA. This is an excellent post by the researchers who developed QLoRA. It provides a series of resources, Colab notebooks on how QLoRA, bitsandbytes and 4-bit quantization make LLMs more accessible.

The LIMA paper: This is pretty amazing and a potential game changer? In this paper, the researchers @MetaAI demonstrate that, given a strong pretrained language model, remarkably strong performance can be achieved by simply fine-tuning on just 1,000 carefully curated training examples. Read more here: LIMA: Less Is More for Alignment.

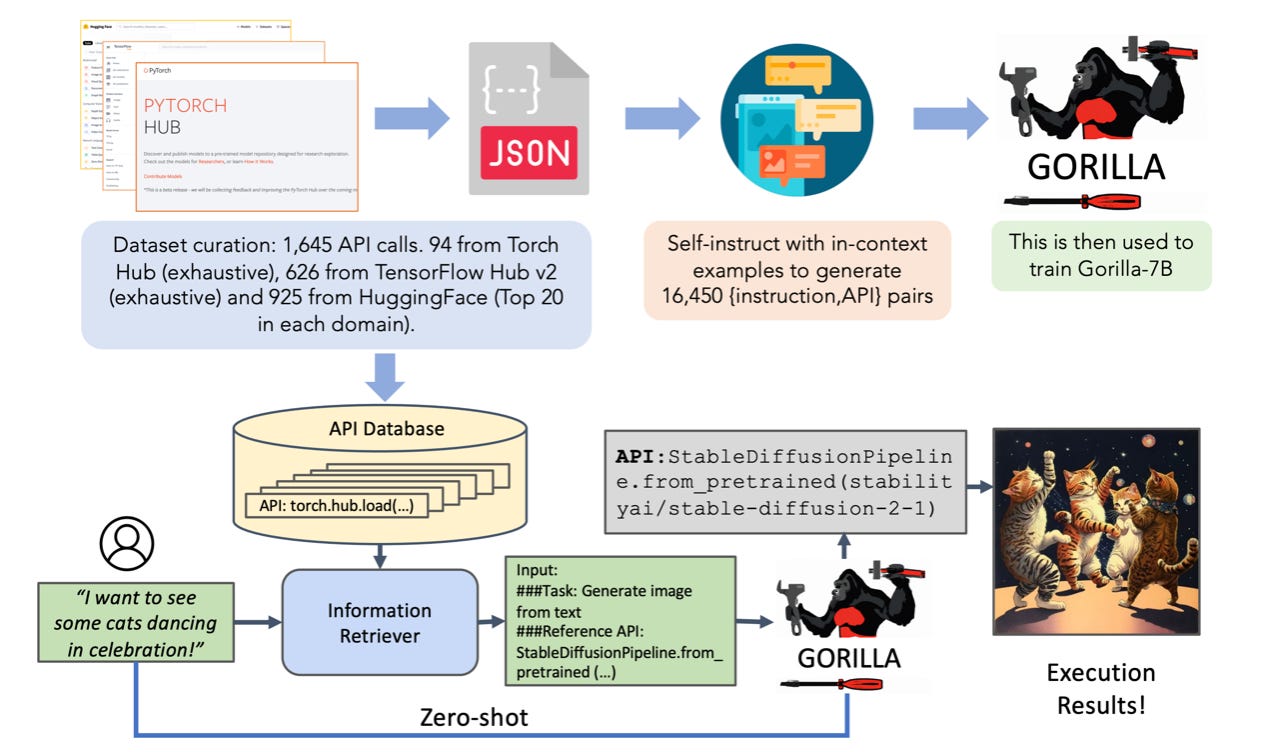
The new fine-tuned GORILLA model. This new model surpasses the performance of GPT-4 on writing API calls. Zero-shot Gorilla outperforms GPT-4, ChatGPT and Claude. Gorilla is extremely reliable, and significantly reduces the hallucination errors. Read more here: GORILLA, a finetuned LLaMA-based model.
Finetuning an LLM on custom data. A great post describing the step by step process, from installation to model download, and data preparation to fine-tuning. In this case, they use Lit-Parrot, a nanoGPT based implementation of the GPT-NeoX. Checkout: How To Finetune GPT-like LLMs on a Custom Dataset.
How to finetune Redpajama. Redpajama is an open-source clone of LLaMA. together.xyz has just released the 3B and 7B RedPajama models. Both come with a base model and a couple of finetuned variants (an instruction-tuned variant and a chat-tuned variant). All released under Apache-2.0 . In this notebook, @johnrobinsn shows how to finetune the RedPJ model into an "Instruction Following" variant using the Alpaca dataset.

Have a nice week.
10 Link-o-Troned
the ML Pythonista
the ML codeR
Deep & Other Learning Bits
AI/ DL ResearchDocs
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.