
Data Machina #205
Multimodal AI. Otter. Video-LLaMA. Video-ChatGPT. Google AI Studio. OpenMMLab Magic. Daft. Spotlight. CoVIz. OptML.
Multimodal AI: An Update. A whole range of specialised AI/ ML models are converging into multimodal AI, much faster than many researchers would have expected say 2 years ago. There’s so much going on in multimodal AI! Here’s some interesting recent stuff on multimodal AI:
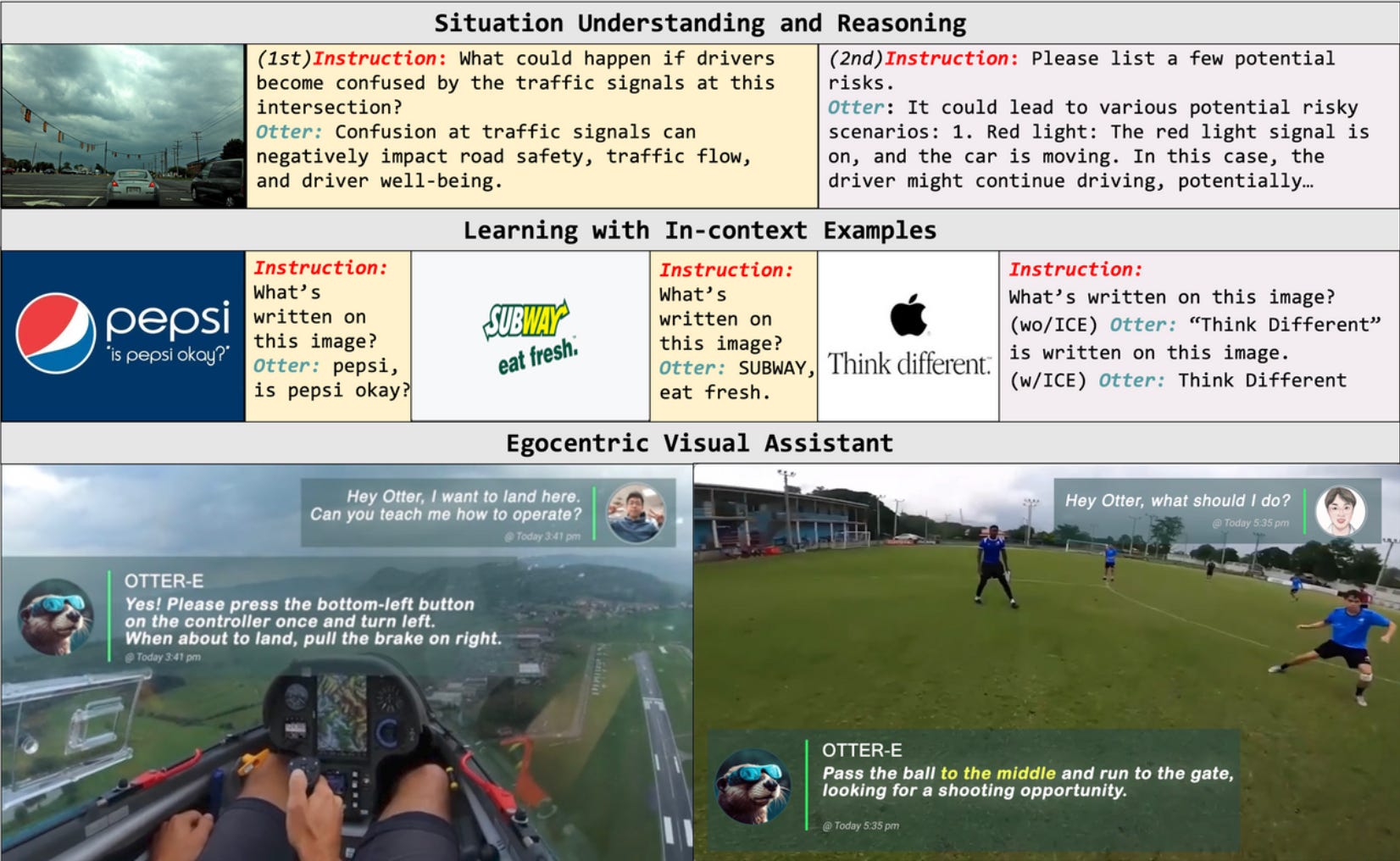
New powerful multimodal models. A great example of this is Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo). Otter is trained on the MIMIC-IT dataset with multimodal in-context instruction tuning.
CAV-MAE (contrastive audio-visual masked autoencoder). Another new multimodal model developed by researchers at MIT and UniofTexas. The researchers claim that by combining self-supervised learning, contrastive learning and masked data modeling, audio-visual tasks with multimodal data can be scaled without the need for data annotation.

New multimodal AI models for video. Video -and all its facets like video understanding and segmentation- is for many reasons an ideal target for multimodal AI. There’s a new breed of powerful models for video emerging. Checkout these 2:
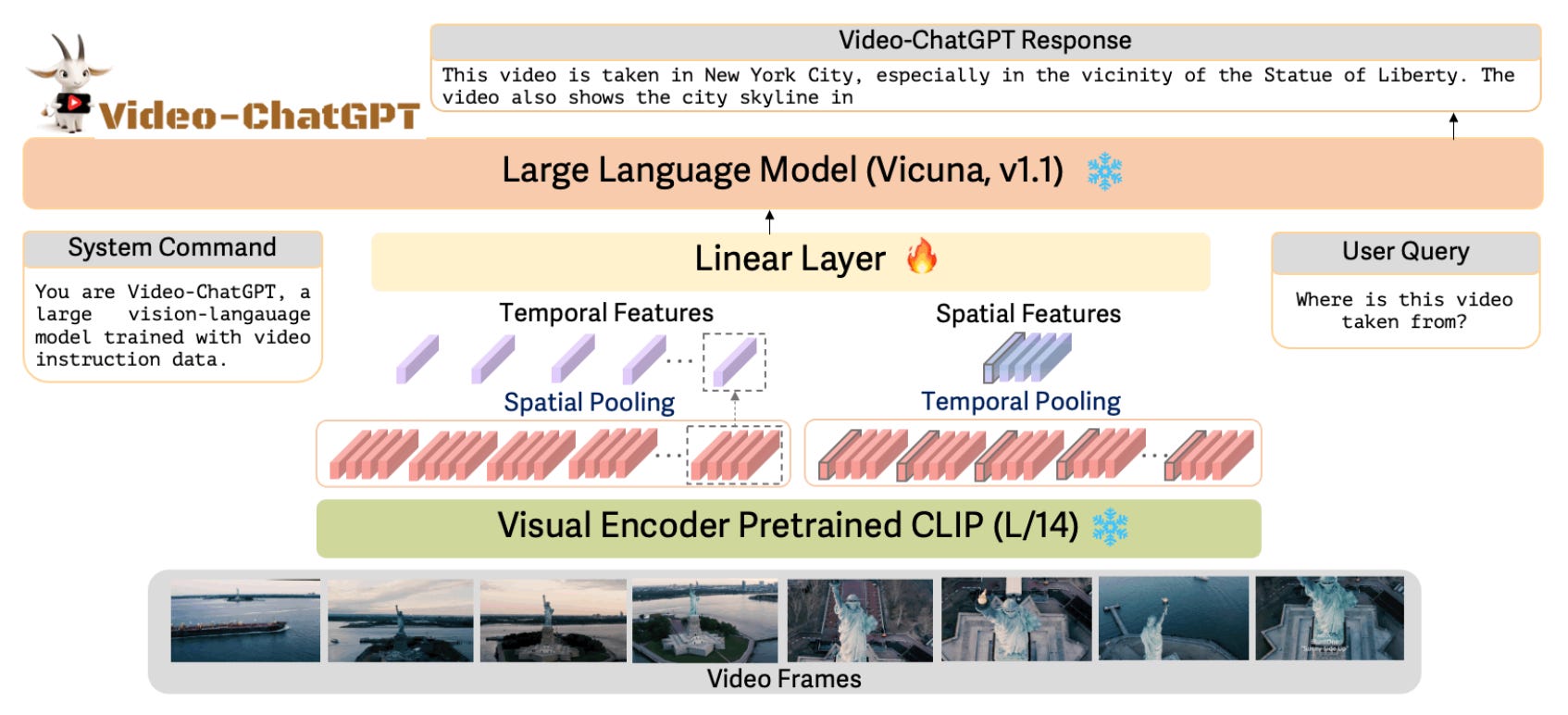
Video-ChatGPT - A new video conversation model capable of generating meaningful conversation about videos. It combines the capabilities of LLMs with a pretrained visual encoder adapted for spatiotemporal video representation.
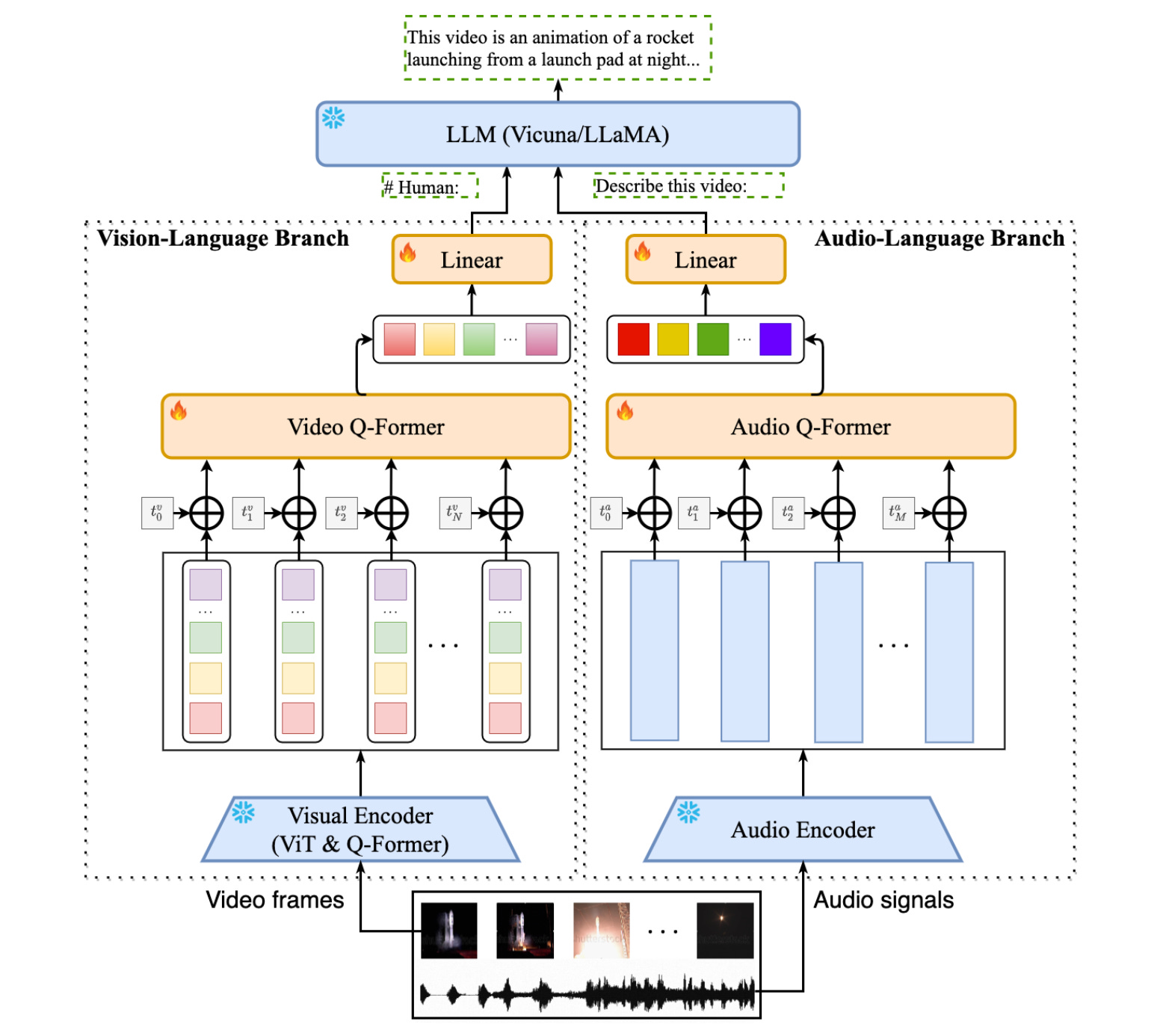
Video-LLaMA - a An Instruction-tuned audio-visual LM for video understanding. Video-LLaMA is built on top of BLIP-2 and MiniGPT-4. It is composed of two core components: (1) Vision-Language (VL) Branch and (2) Audio-Language (AL) Branch.
New toolkits for multimodal AI. Multimodal AI brings a whole set of new challenges in terms of aspects like: design and development, model and data workflows, MLOps, composition, interaction, inter-operability, and interpretability. Two new toolkits:
OpenMMLab Magic - A multimodal advanced toolbox for Generative AI. Magic comes out of the box with: Easy-to-use APIs, awsome model zoo, diffusion models, text-to-image generation, image/video restoration & enhancement…
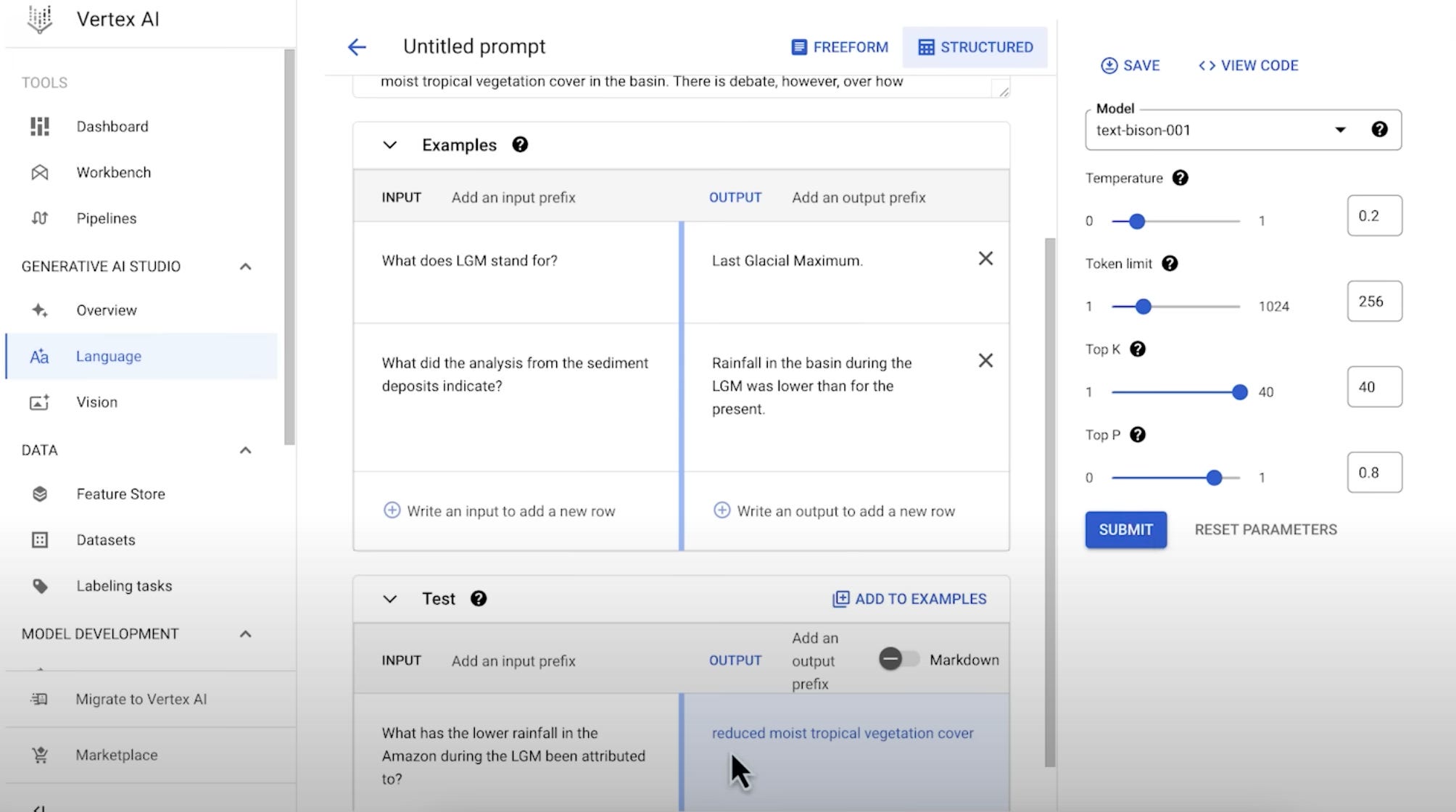
Google Generative AI Studio - Google just announced the general availability of this tool. It uses Google’s multimodal foundation models as APIs including PaLM, Imagen, Codey, and Chirp. Runs on Vertex AI.A simple, easy-to-use interface for prompt design, tuning, and deployment.
New tools for wrangling multimodal datasets. Multimodal AI requires new tools that are scalable, fast, and cheap to wrangle with massive multimodal data. Here’s two new additions to multimodal data wrangling:
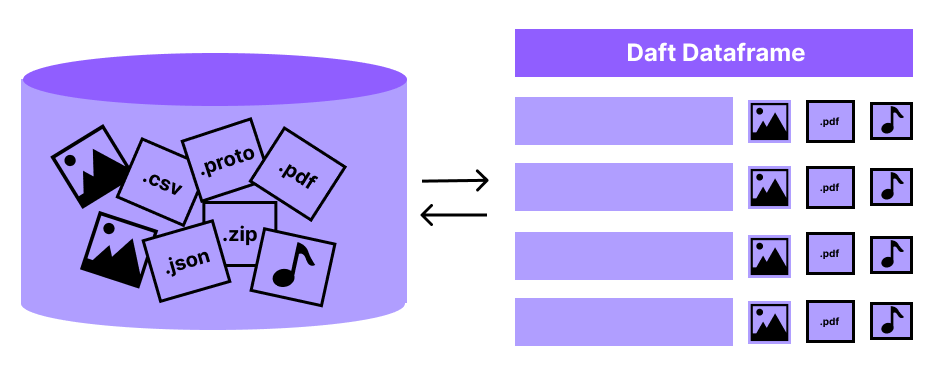
Introducing Daft - Daft is a new, Pythonic high-performance distributed dataframe library for multimodal data. It’s like Polars, pandas and Spark on steroids. It leverages Rust and Arrow, and it’s faster and more scalable than Spark or Dask.
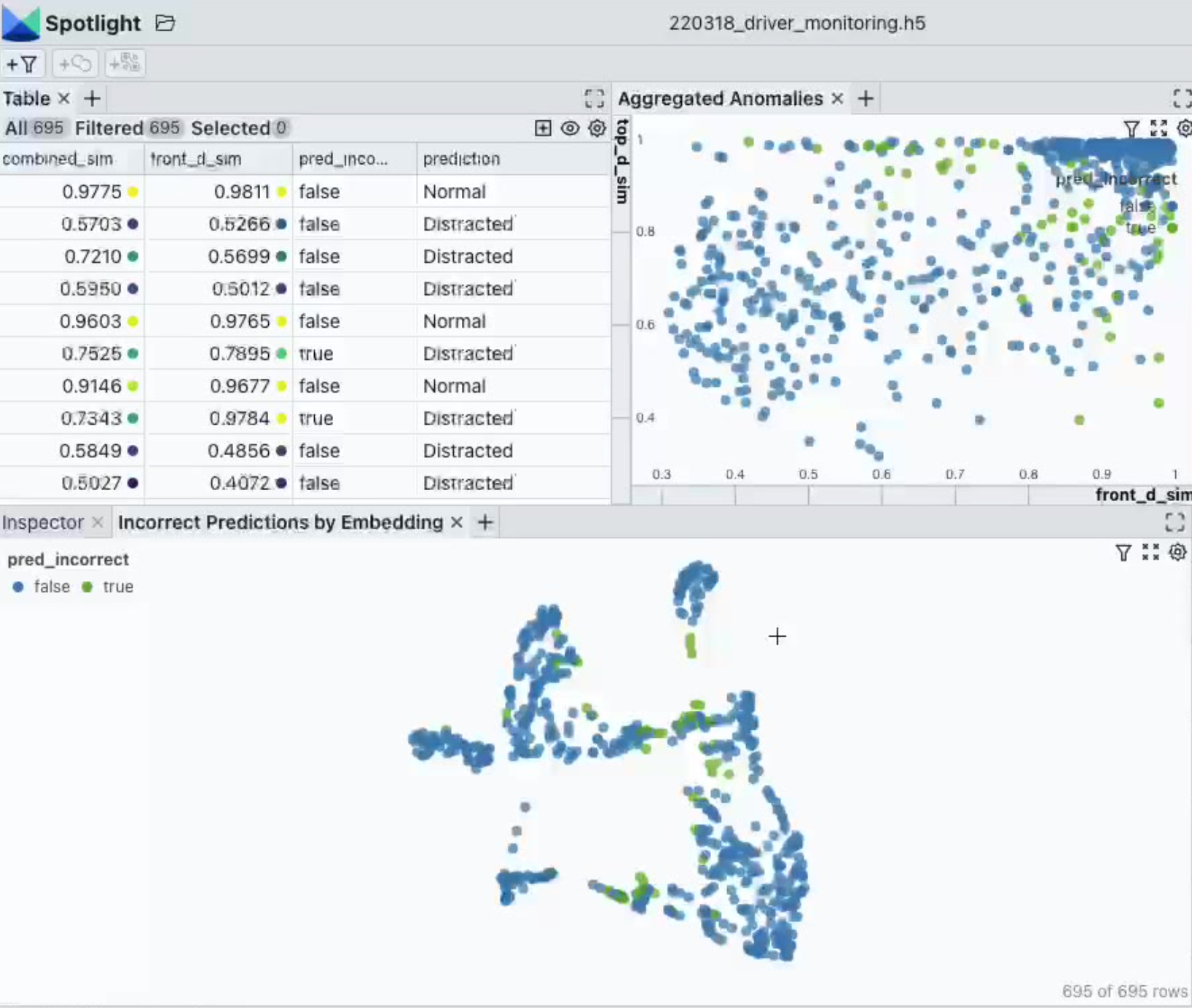
Spotlight. An open source, drop-in solution for all the data inspection and interaction needs in your data-centric AI workflows and multimodal data.
Upcoming conferences on multimodal AI. Until recently, the norm has been to organise conferences and workshops on specialised AI/ML topics. There has been an increase in multimodal AI conferences and workshops. Check out these 3:
Have a nice week.
10 Link-o-Troned
the ML Pythonista
How to Fine-tune BERT for Text Classification on AWS Trainium
[tutorial] Parameter-efficient Fine-tuning of GPT-2 with LoRA
Build an AI Sales Assistant w/ Deep Lake, Whisper, LangChain & GPT
Deep & Other Learning Bits
AI/ DL ResearchDocs
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
this is way better than many other ai newsletters I've seen - thank you!
Conferences, courses (including free courses), and books (including free books): I rarely see these listed with regularity on other stacks/newsletters. Please continue including these resources.