
Data Machina #207
Steering LLMs. LMQL. Guardrails. Direct Preference Optimization. Sequential Monte Carlo. Fast SAM. AudioPaLM. MAGVIT. New Midjourney 5.2. How RLHF works.
Taming the Stochastic Beast: Beyond Prompting. I’m in this summer party mingling with smart business & tech people. Everyone is merrily sipping potent cocktails while proclaiming their seemingly vast expertise in ChatGPT prompting. I approach a group of 3 blokes, and just for fun I ask: ”How would you control the outputs from a stochastic parrot?” I get blank faces. Then one of them asks me: “Another Daiquiri perhaps?”
A while ago researchers at Berkeley & Cornell Unis published this paper: Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts Most definitely, I’m going to send the paper to the people that attended the summer party.
LLMs in business. One thing is to do fancy innovation experiments in your company with ChatGPT. Quite another thing, is to consistently get accurate, reliable, trustworthy outputs for your business from an LLM in production, at scale, cost-efficiently.
Beyond prompting: steering. Using some clever or advanced prompting like: in-context learning, CoT, ToT, ReAct, self-consistency… won’t be enough to always getting accurate, reliable outputs consistently. And fine-tuning, reward modelling, and (for the rich) RLHF, may still not deliver what your business needs. For this reason, many investors, researchers and companies are setting there sights in “LLM steering” or a series of new methods and tools to improve LLM consistency, reliability in a time and cost efficient, scalable way.
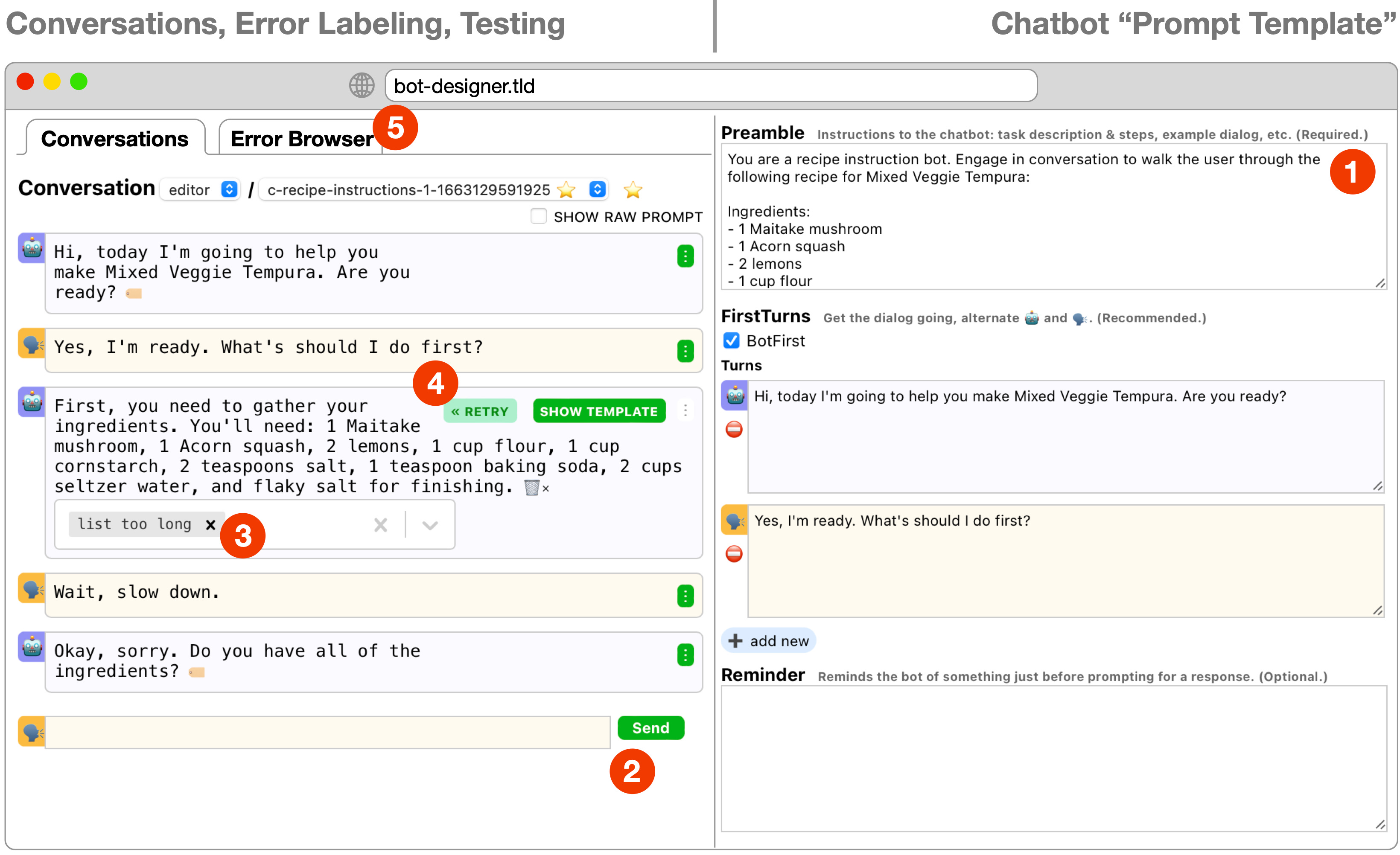
Detecting problematic prompts. A key aspect of your LLMOps should be monitoring your model’s prompt/response embeddings performance. Here is a new tool to monitor LLM’s outputs and detect problematic prompts.
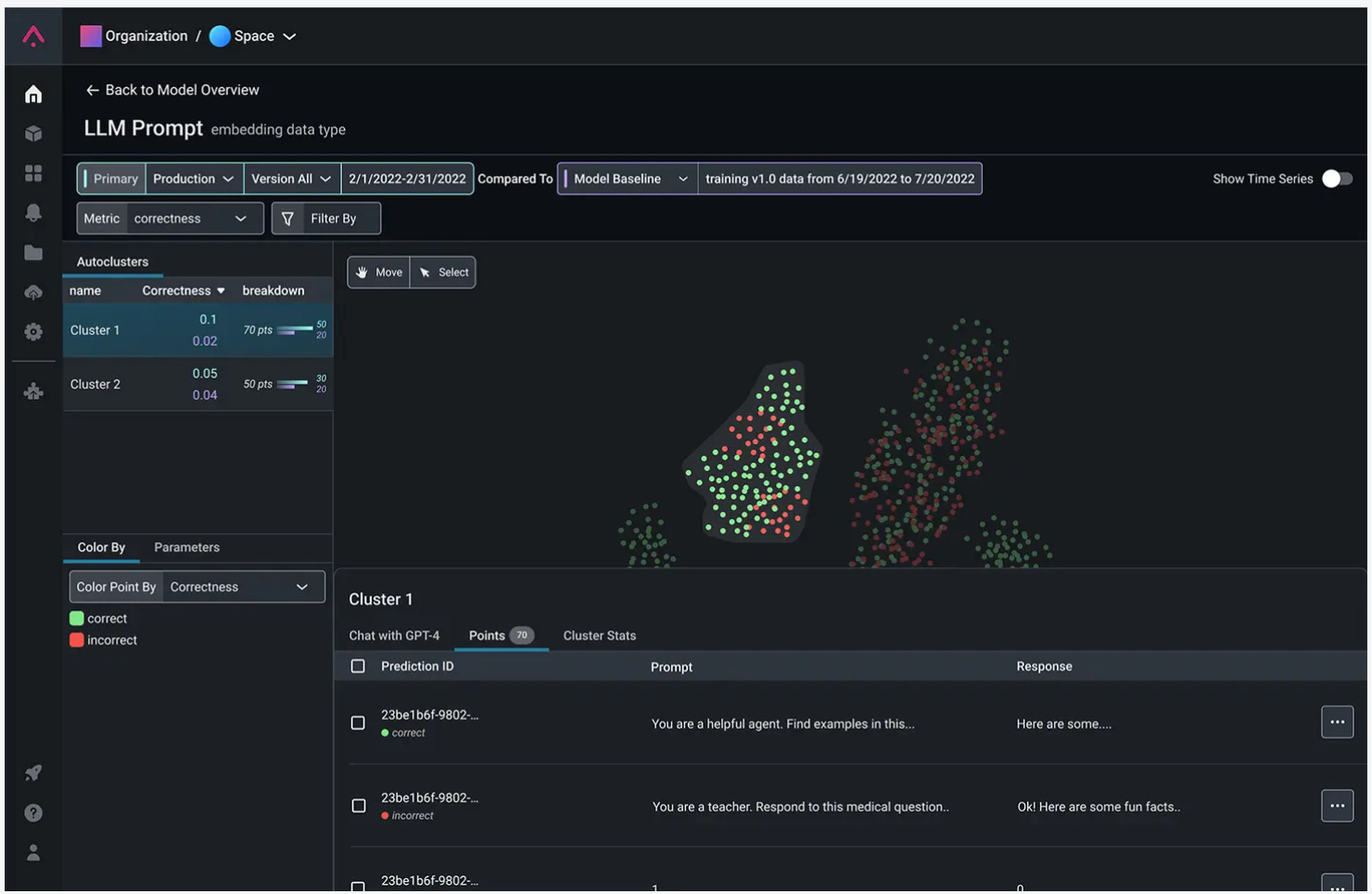
Start by grounding the LLM. Grounding is the process of using LLMs with information that is use-case specific, relevant, and not available as part of the LLM's trained knowledge. Researchers at MSR suggest that you should first explore the possibilities of Retrieval Augmented Generation before resorting to fine-tuning.
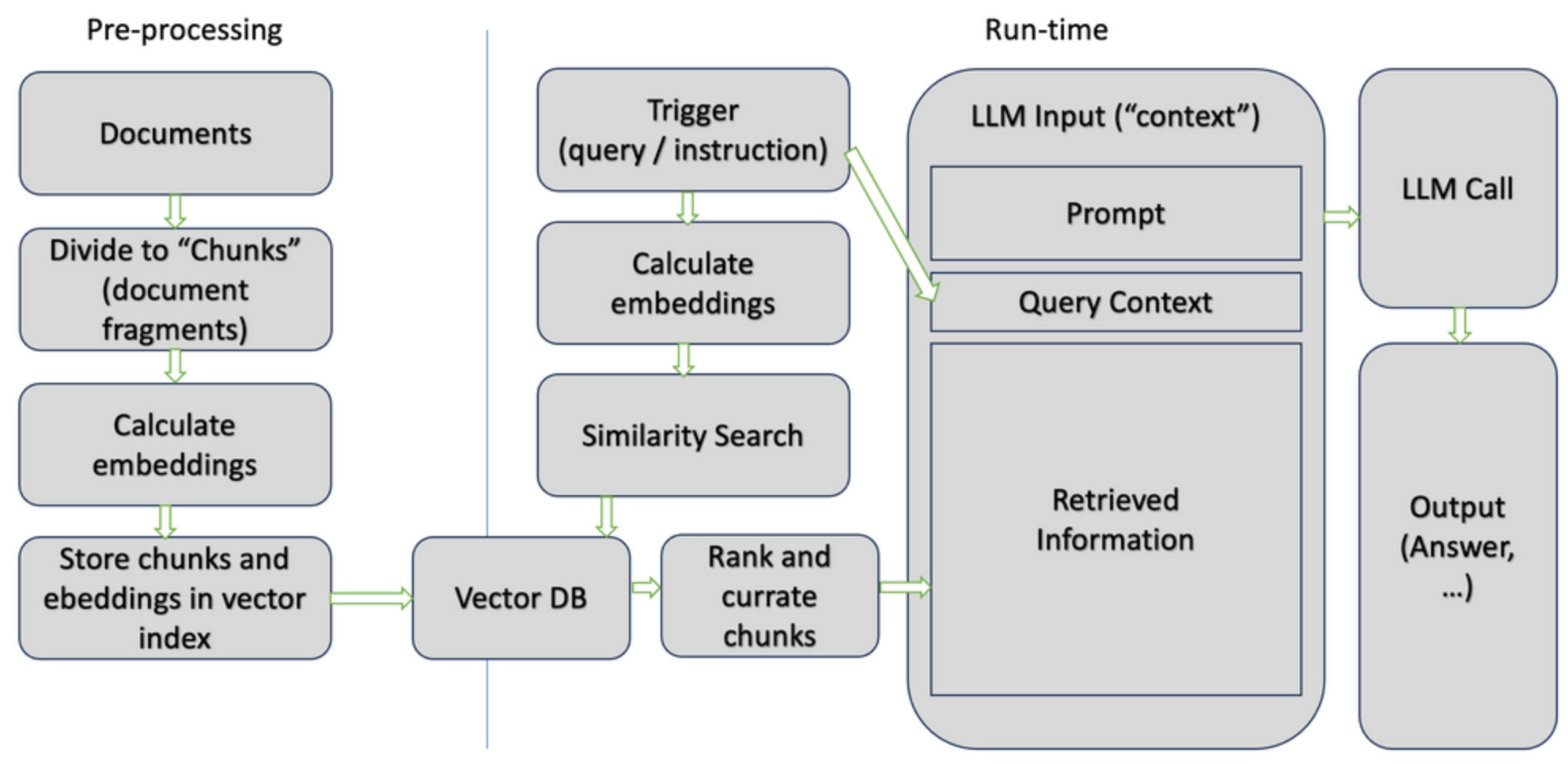
Use a DSL for constraining LLM outputs. Another approach is to use a DSL to specify high-level, logical constraints over the LM output. This allows to enforce many constraints strictly, making it impossible for the model to generate content that does not satisfy the requirements. Checkout: LMQL: A programming language for LLMs
Put some guard-rails around the LLM. Check this new Python package called Guardrails. It lets you add structure, type and quality guarantees to the outputs of LLMs, and also takes corrective actions (e.g. reasking LLM) when validation fails.
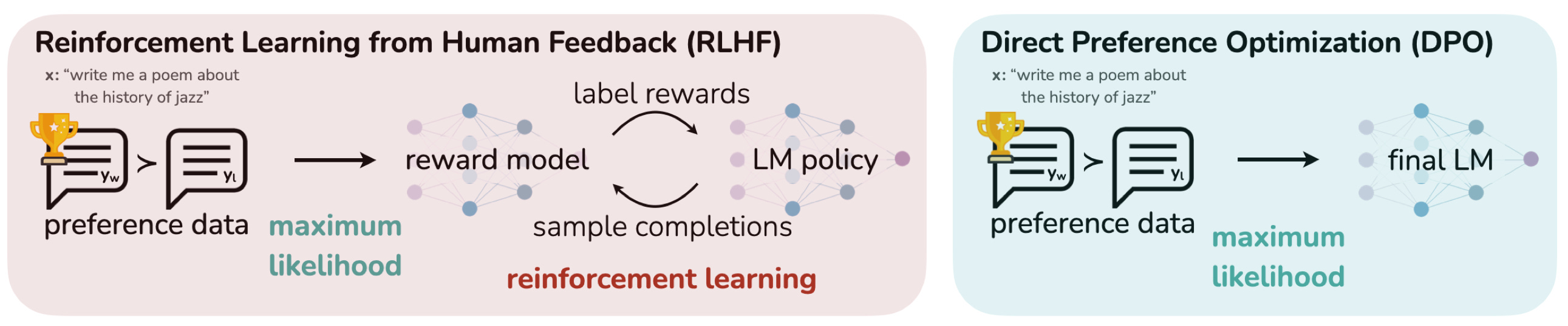
Apply DPO: A new policy algorithm. imo this is a very important development.…In late May, Stanford researchers introduced Direct Preference Optimization (DPO): a new stable, performant and computationally efficient policy, that eliminates the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning. Paper: Direct Preference Optimization: Your Language Model is Secretly a Reward Model
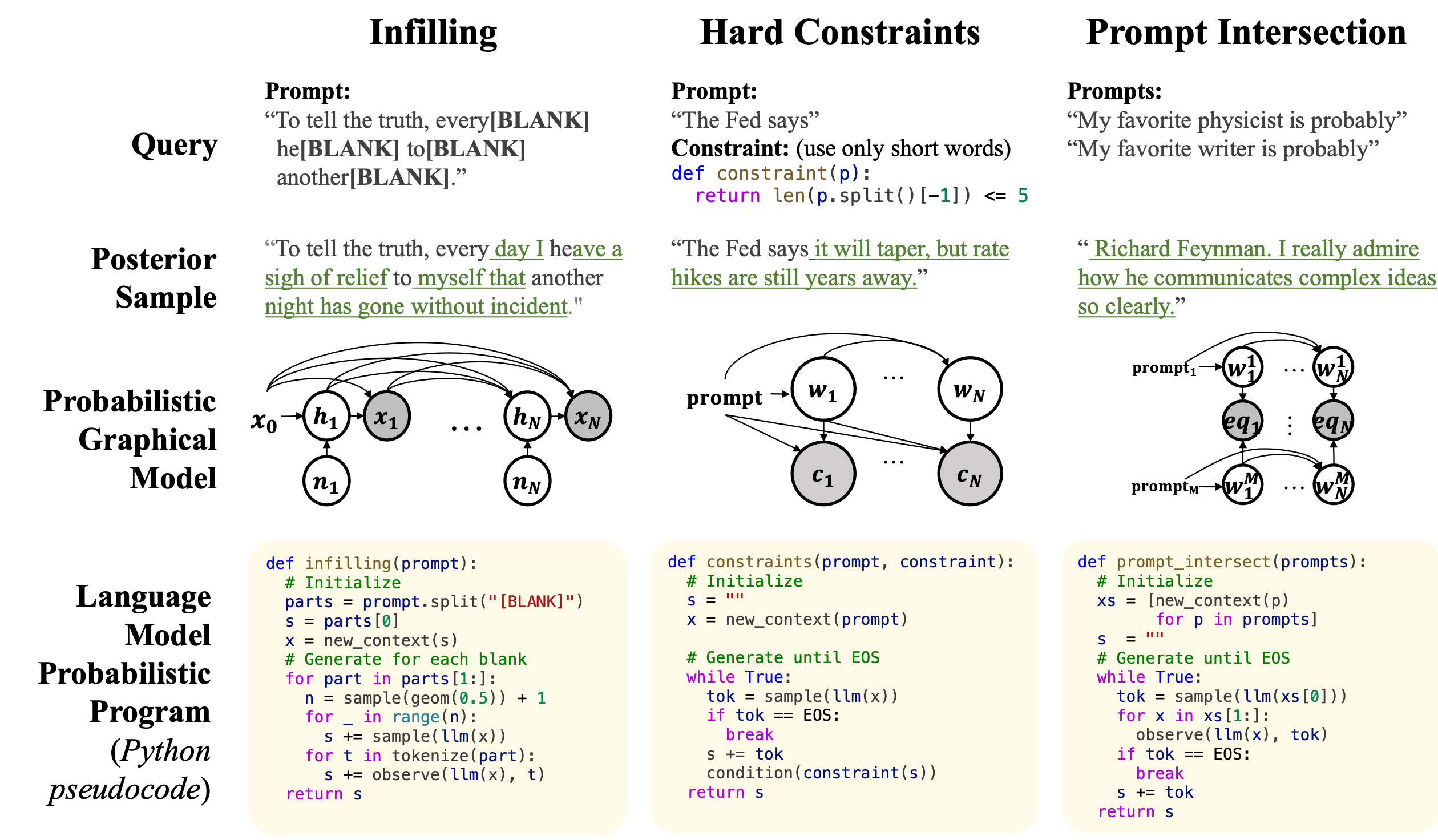
Steer the LLM with Monte Carlo. Researchers at MIT, just released a new inference-time approach to enforcing syntactic and semantic constraints on the outputs of LLMs, called sequential Monte Carlo (SMC) steering. Using SMC you can steer LLMs to solve diverse task with create control of the outputs. Paper, repo: Sequential Monte Carlo Steering of LLM using Probabilistic Programs
Have a nice week.
10 Link-o-Troned
MAGVIT: An Amazing, New Video Transformer (demo, paper, code)
[free book] Information Theory: From Coding to Learning (pdf, 599 pages)
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.