

Data Machina #209
Data Machina #209
LLM Temp and Context Size. Ulimiformer. LongNet 1Billion. Focused Transformer. 100K Chatbot. Code Interpreter Intro. CrunchGPT. CodeGen 2.5. StyleDrop PyTorch. LongEval. AI Agents on Local GPU.
LLM Temperature and Context: It Varies (like temp in hotel rooms.) So I decided to burn my surplus of frequent-flyer points for a stay at this 5* hotel. It’s 3am and I can’t sleep. The heat in this apartment-size room is unbearably tropical.
I call the front-desk. I complain: the room is not cool enough, the #! @*&%!! thermostat doesn’t work. The receptionist, deflects my complaint: “We’re aware of A/C issues due to the heat wave. Our hotel was not originally built to deal with climate change.” I explode: “??? WAAAT!! Please, fix the issue! It’s 3am, you charge zillions for a night stay, and I can’t sleep because the bloody A/C won’t work!”
A technician quickly shows up with a temp probe. She opens the A/C box, probes in, and then solemnly says: “The A/C is fine sir: It reads 19.2 °C.” I reply: “Really? look at the wall thermostat: It shows 25.3 °C!” I persist: ”Just take a temp measure in the bedroom ” …the probe reads 27.5 °C!!
Unfazed, the technician hits me : “The A/C output is impacted by the size and config of the room, hence variable temperatures [smiles]”…
So what’s temperature, really? Yeah, It varies… different context size, different outputs, different temperatures… In LLMs, tweaking the temperature knob is a bit of an art. This is a nice intro post on What is Temperature in NLP / LLMs?
I like this vid, it’s an overly simple explainer but to the point: Understanding how LLM temperature and context length affect outputs/results.
More in-depth, in this blog post on Token selection strategies: Top-K, Top-p, and Temperature, Peter explains how these parameters influence the output of an LLM.
There are lots of threads out there on poor LLM outputs and reproducibility given a set temperature. Here is a thread: Observing discrepancy in completions with temperature = 0
Token size arms race. Computation, token-size and quality of output... There is the arms race happening to massively increase the token size, as if though that could solve “everything”
The 500K token transformer. Unlimiformer is a method for augmenting pretrained encoder-decoder models with retrieval-based attention (RAG), without changing the mathematical definition of attention. This allows the use of unlimited length inputs with any pretrained encoder-decoder. Paper: Unlimiformer: Long-Range Transformers with Unlimited Length Input

LongLLaMA and the 256K Focused Transformer (FoT). A few days ago, researchers at DeepMind et. al introduced a method -inspired by contrastive learning- that allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. The researchers claim the model improves tasks requiring a long context. Paper: Focused Transformer: Contrastive Training for Context Scaling

The 1 Billion token transformer. This week, MS researchers introduced a transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. This method uses dilated attention mechanism, which expands the attentive field exponentially as the distance grows. Paper: LongNet: Scaling Transformers to 1,000,000,000 Tokens




Massive token size and model degradation. This an intriguing new paper. The researchers claim that LLM performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Paper: Lost in the Middle: How LMs Use Long Contexts.
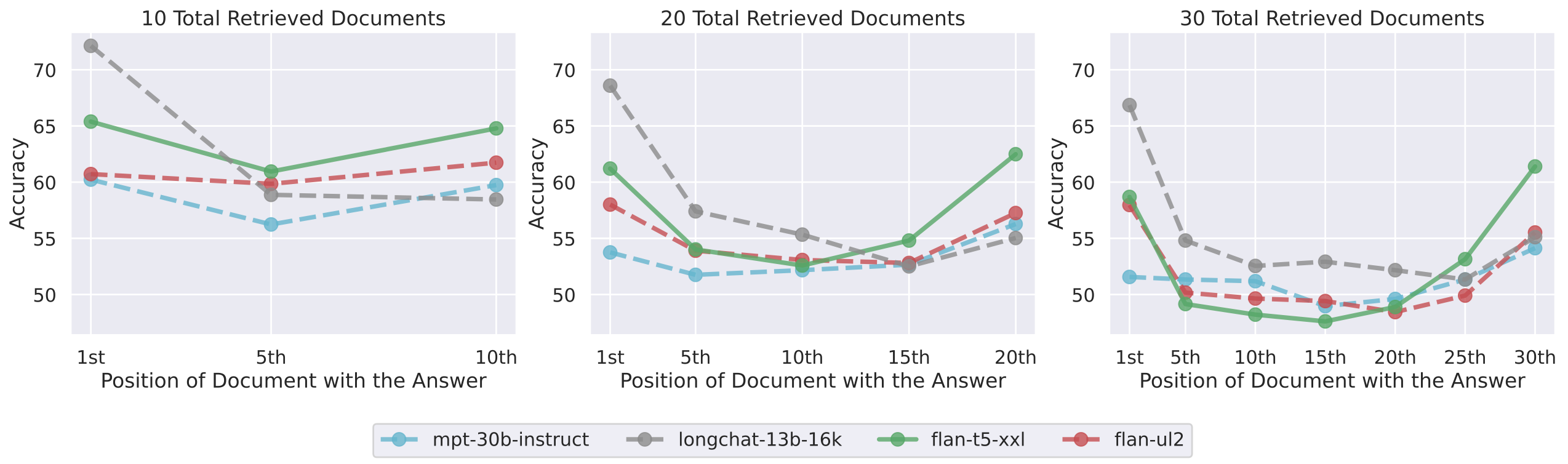
The researchers also claim that GPT-3.5 Turbo 16K is the “best” model for Q&A tasks, and Anthropic Claude 100K is the “best” model for retrieval tasks.
Speaking of Anthropic, this is a quick tutorial on how to build a 100K token context chatbot with Claude.
Mega token size and new research on long-form summarisation validation. Imagine 20 analysts in an insurance company, overloading the 100K token model with very long-form docs and running summarisation task on that. The LLM spits out the long-form summary…but: Who are the ever resourceful, clever humans who’ll validate the veracity, accuracy of the long-form summaries?…And How? The evaluation of long-form summaries is a new area of research. Paper: LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization
Bored to death by LLMs? I don’t blame you. Leave aside the stochastic parrots for a moment, and grab these two free books on ML/DS fundamentals:
On the PCA. The venerable PCA is still alive and kicking; very much used in real-world, everyday ML. This is a deep dive into PCA but also written in a beautiful narrative fashion. Get the book here: Unraveling Principal Component Analysis.
On statistical learning & Python apps. Making sense of complex data and applying the fundamentals still remains. An Intro to Statistical Learning with Apps in Python, Jul 2023 (pdf, 601 pages)
[So I bluntly placated the hotel manager at the lobby. I got my points back but I didn’t sleep in two days.] Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
El Robótico
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.