
Data Machina #218
Little, Efficient AI Models. TinyLLama 1.1B. React Code 1.6B SOTA. Persimmon 8B. FLM-101B. Physics Informed NNs. Text2SQL. Code Interpreter in the Term. Q-Transformer. RLAIF. VideoGen SOTA Txt2Vid
New Tiny Little and More Efficient AI Models. The quest for smaller, more efficient AI models is not going to stop any time sooner. Some amazing little and efficient models are popping up everywhere. This week I discovered 5 interesting models. Also a couple of notes on LLM reliability and variability at the end.
Pre-training TinyLlama-1.1B: This project aims to pre-train a 1.1B Llama model on 3 trillion tokens. With some proper optimisation, the researchers can achieve this within a span of "just" 90 days using 16 A100-40G GPUs. The training has started on 2023-09-01…Checkout TinyLlama-1.1B: An open endeavour to pretrain a 1.1B Llama model on 3 trillion tokens.

Introducing React Code 1.6B: This is a code model with infill real-time code completion and chat. It achieves SOTA performance among the code LLMs, coming closer to HumanEval as Starcoder, being 10x smaller in size. It can deal with 20 programming languages and has a 4096 tokens context. It’s been released with permissive licensed code and available for commercial use. Read more: React Code, a 1.6B State-of-the-Art LLM for Code
Leveraging Falcon-7B: Researchers at Georgian evaluated different methods to leverage Falcon-7B, i.e. in-context learning and fine-tuning with QLoRA, and found fine-tuning to outperform other methods across both tasks of classification and summarisation. The researchers found that Falcon-7B to perform better than Google Flan-T5-Large and BERT family. Furthermore, Falcon-7B performs particularly well when the amount of available labeled data is limited. See blog and repo: The Practical Guide to LLMs: Falcon
Open sourcing Persimmon-8B: The researchers claim this is the most capable open-source, fully permissive model with fewer than 10 billion parameters. It’s released under Apache license. It has a 16K context size. The base model exceeds other ~8B models and matches LLaMA2 performance despite having been trained on only 0.37x as much data as LLaMA2. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. Read more: We’re open-sourcing Persimmon-8B.

Cost-efficient FLM-101B: Not small but a very efficient model that was trained with the model growth technique. The model rapidly acquires knowledge on a small-scale model(16B) in the early stages of training and gradually scales up to 101B, resulting in a cost-effective 100B-scale LLM training(at a $100K cost). Read more: FLM-101B: An Open LLM and How to Train It with $100K Budget.
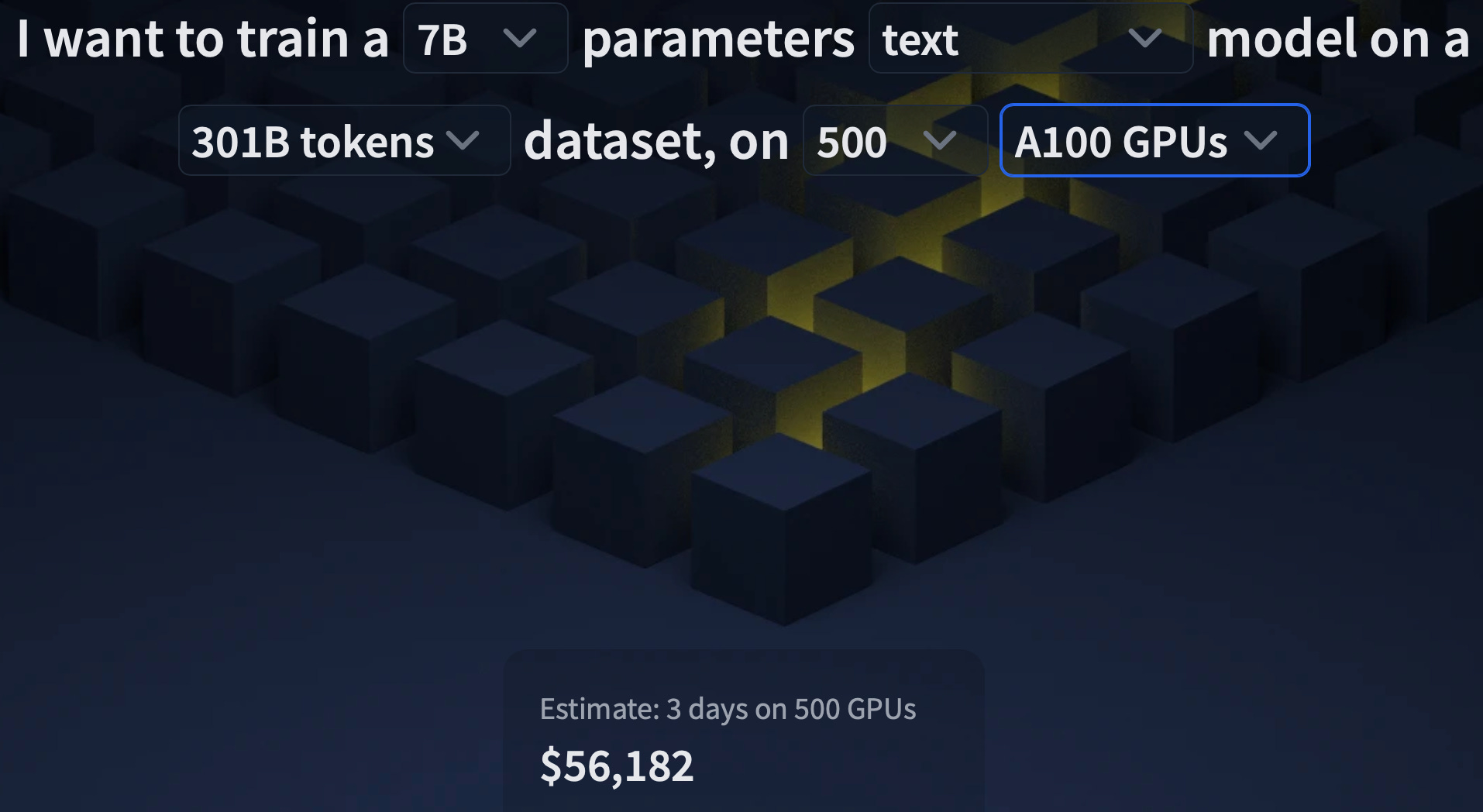
Speaking of the cost of training LLMs. Hugging Face recently announced a service to train LLMs on their infra. It comes with a little cost calculator that gives you a rough idea of cost… How much a 7B LM model trained on a 301B tokens dataset with 500 A100? ca. $56K in 3 days. Check it out: Hugging Face LLM Training Cluster as a Service.
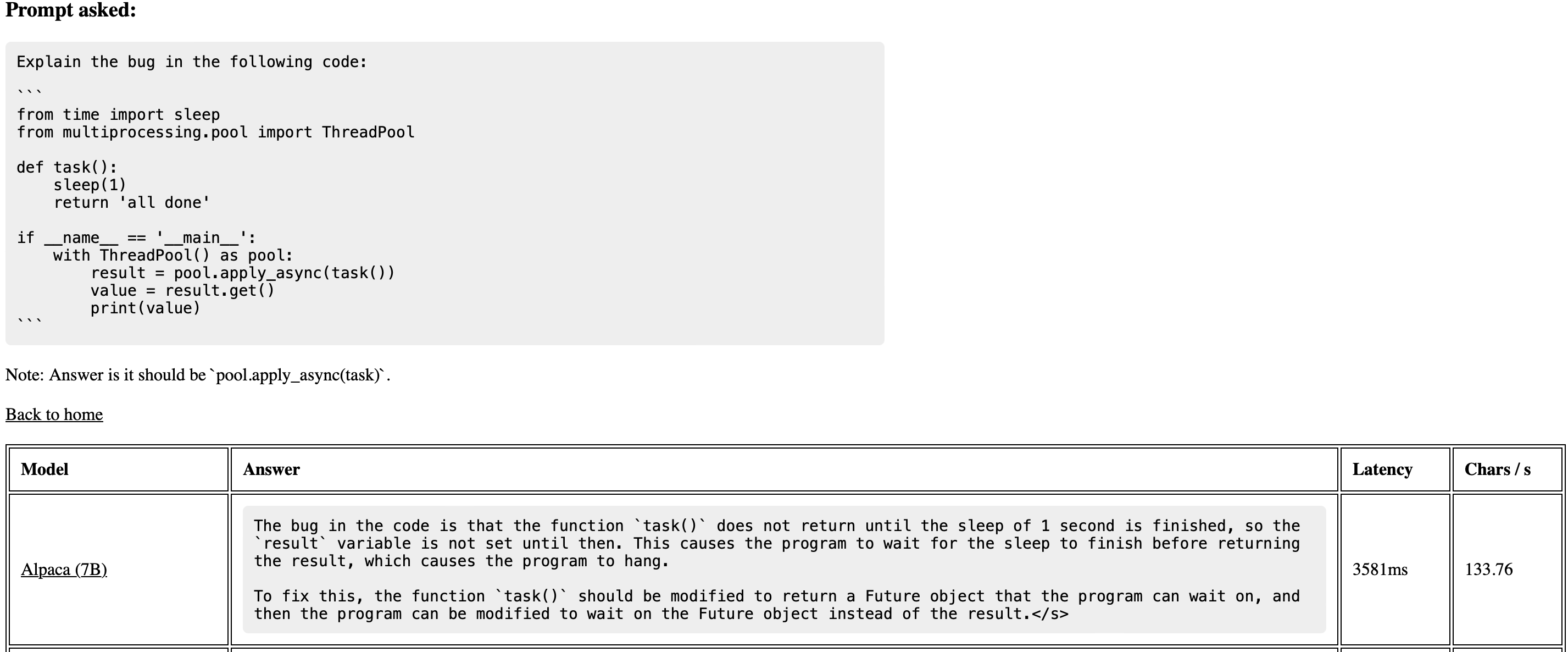
Because LLMs are still not very prod ready, reliable. Yeah, if you are involved in real-world, enterprise projects using LLMs for stuff like summarisation, info retrieval and doc Q&A: you know what I mean. This still requires a lot of iterations, and syncing many moving parts to obtain reliable, accurate, business relevant results.
Asking 60+ LLMs 20 Qs. Vince had this brilliant idea of writing a script that asks the same prompts to 60 LLMs. The results are quite revelatory and interesting. This is arguably a “better” practical way to evaluate LLM outputs than some of those artificial evaluation benchmarks :-) Blog: Asking 60+ LLMs a set of 20 questions
Abstractive summarisation and hallucinations. Evaluating abstractive summaries is challenging. How do we check summaries for hallucination? In this brilliant post, Eugene discusses the 4 dimensions for evaluating abstractive summarisation before diving into 4 key metrics. Then he describes methods to detect hallucination, using natural language inference (NLI) and question-answering (QA). Blog: Evaluation & Hallucination Detection for Abstractive Summaries
Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
Google - RLAIF: Scaling RL from Human Feedback with AI Feedback
Baidu - VideoGen: SOTA High Definition Text-to-Video Generation
Deepmind- LLMs are Optimisers [AI Prompts Better than Human Prompts]
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.