

Data Machina #225
Data Machina #225
GenAI and xAI. State of Open Source AI. ConvNets vs. ViTs. DALL-E 3 Prompting. Open 8K Text Embeddings. DB-GPT. MemGPT. Stanford Graph Learning Workshop.
GenAI and Explainable AI (xAI). Despite so many techniques and approaches "to guide and align the GenAI model outputs,” the fact is that GenAI models (naturally) still generate many unexpected, surprising, or totally wrong outputs. Increasingly, more than ever, I hear a lot of business people asking for “model explanations” and “interpretable models that can be explained.” Once the GenAI phase of hype & exploration fades away, we’ll see xAI becoming a priority. Here are a few notes on xAI:
Introduction to Interpretable Machine Learning. In this excellent free book, you’ll learn the concepts of interpretability, and interpretable models such as decision trees, decision rules and linear regression, as well as interpretable DL models. The focus of the book is on model-agnostic methods for interpreting black box models such as feature importance and accumulated local effects, and explaining individual predictions with Shapley values and LIME. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable

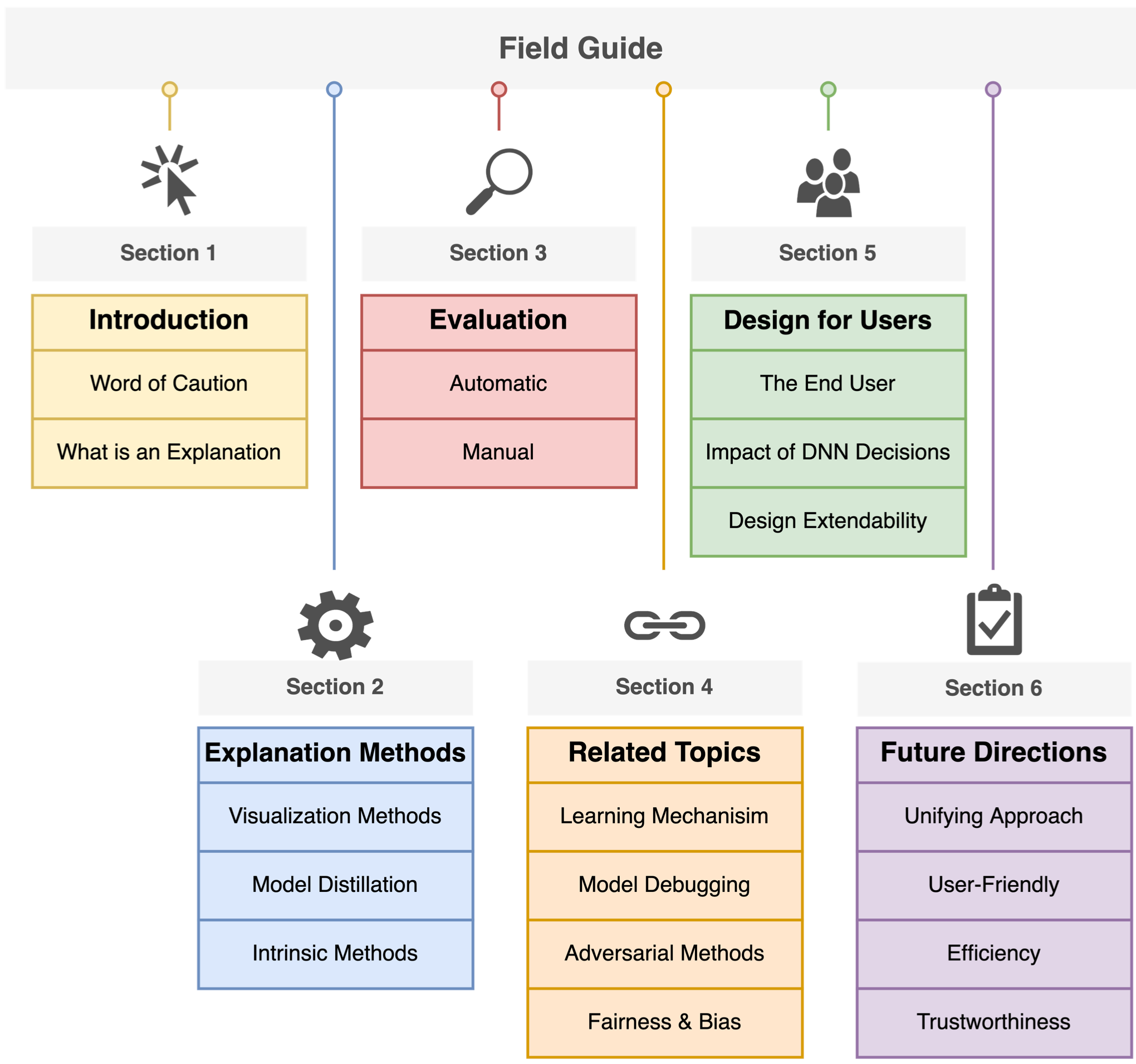
What is explainable Deep Learning? This is a field guide on explainable DL aimed at those uninitiated in the field. The field guide: i) Introduces three simple dimensions defining the space of foundational methods that contribute to explainable deep learning, ii) discusses the evaluations for model explanations, iii) places explainability in the context of other related deep learning research areas, and iv) finally elaborates on user-oriented explanation designing and potential future directions on explainable DL: Explainable Deep Learning: A Field Guide for the Uninitiated.
Machine Unlearning to improve interpretable AI. Machine unlearning is a field of research with 2 objectives: one, to deliberately diminish the model's performance on specified "unlearned" tasks, and second, to ensure that the model's proficiency is maintained or even enhanced on certain "retained" tasks. In this extensive article, Nicky show how applying interpretability techniques as unlearning strategies could improve the interpretability of language models Machine Unlearning Evaluations as Interpretability Benchmarks

Better tools for explainable AI. Dalex is an R & Python package that xrays any ML model and helps to explore and explain its behaviour, and helps to understand how complex models work. The philosophy behind DALEX explanations is described in this free e-book: Explanatory Model Analysis. Dalex incorporates the latest developments in Interpretable Machine Learning/ eXplainable AI. Checkout the repo, examples, and documentation here: DALEX- moDel Agnostic Language for Exploration and eXplanation

Counterfactual explanations and explainable AI. The use of counterfactuals is becoming quite relevant in AI explainability. A counterfactual explanation of a prediction describes the smallest change to the feature values that changes the prediction to a predefined output. I this workshop, Francesco @ImperialColleges explains how to build Robust Explainable AI: the Case of Counterfactual Explanations (pdf, 74 slides.)

New methods for interpreting and controlling Neural Nets. Codebook Features is a method for training neural networks with a set of learned sparse and discrete hidden states, enabling interpretability and control of the resulting model. Paper, repo, web app: Codebook Features: Sparse and Discrete Interpretability for Neural Networks

Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
QMoE: Compressing 1.6 Trillion Mixture of Experts Model in 1 Bit
Eureka: Zero-shot Code Generation Optimised with Human Rewards
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.