
Data Machina #227
AI Hallucinations. Adversarial attacks on LLMs. Docker's GenAI Stack. ML Parallelism. ULTRA Graph Reasoning. Random Forests in 2023. AWS Fortuna. TimeGPT. Agent Swarms. LlaVA-Plus Multimodal Agents.
On AI Hallucinations. A colleague is doing a demo of a financial compliance RAG, when a Sr. Manager vehemently interrupts: “I’ve seen enough… I want this… what you call… “hallucinations” completely removed from the system.” I explain that you can mitigate, minimise, or reduce the “hallucinations” but not fully remove, stop them. “Right! In that case, I’m not prepared to take that risk, so I’m not funding this prototype anymore.” So the meeting ends abruptly. Then many sad & grinning face emojis pop up in my mobile.
Yes, there are many techniques like: clever ToT prompting and grounding the model, self-consistency, instruction tuning, least-to most prompting, etc… But the key matter is that you won’t remove hallucinations fully. And you’ll have to implement a solid approach to deal with them, especially in enterprise, production apps in which hallucinations are a business risk. Many researchers including Yann LeCun believe that stopping models from hallucinating is unsolvable, because the very nature of auto-regressive generative models.
Understanding AI hallucinations. First, and beyond the layman’s understanding of hallucinations, it’s important to understand what hallucinations are, how they originate and the many types of them. Indeed, there are many types of hallucinations, more than you’d imagine.
In this new, comprehensive paper, the researchers introduce a new innovative taxonomy of LLM hallucinations, they then describe the factors contributing to hallucinations. The paper provides a comprehensive overview of hallucination detection methods and benchmarks, and different approaches to mitigate hallucinations. Paper: A Survey on Hallucination in LLMs: Principles, Taxonomy, Challenges, and Open Questions.
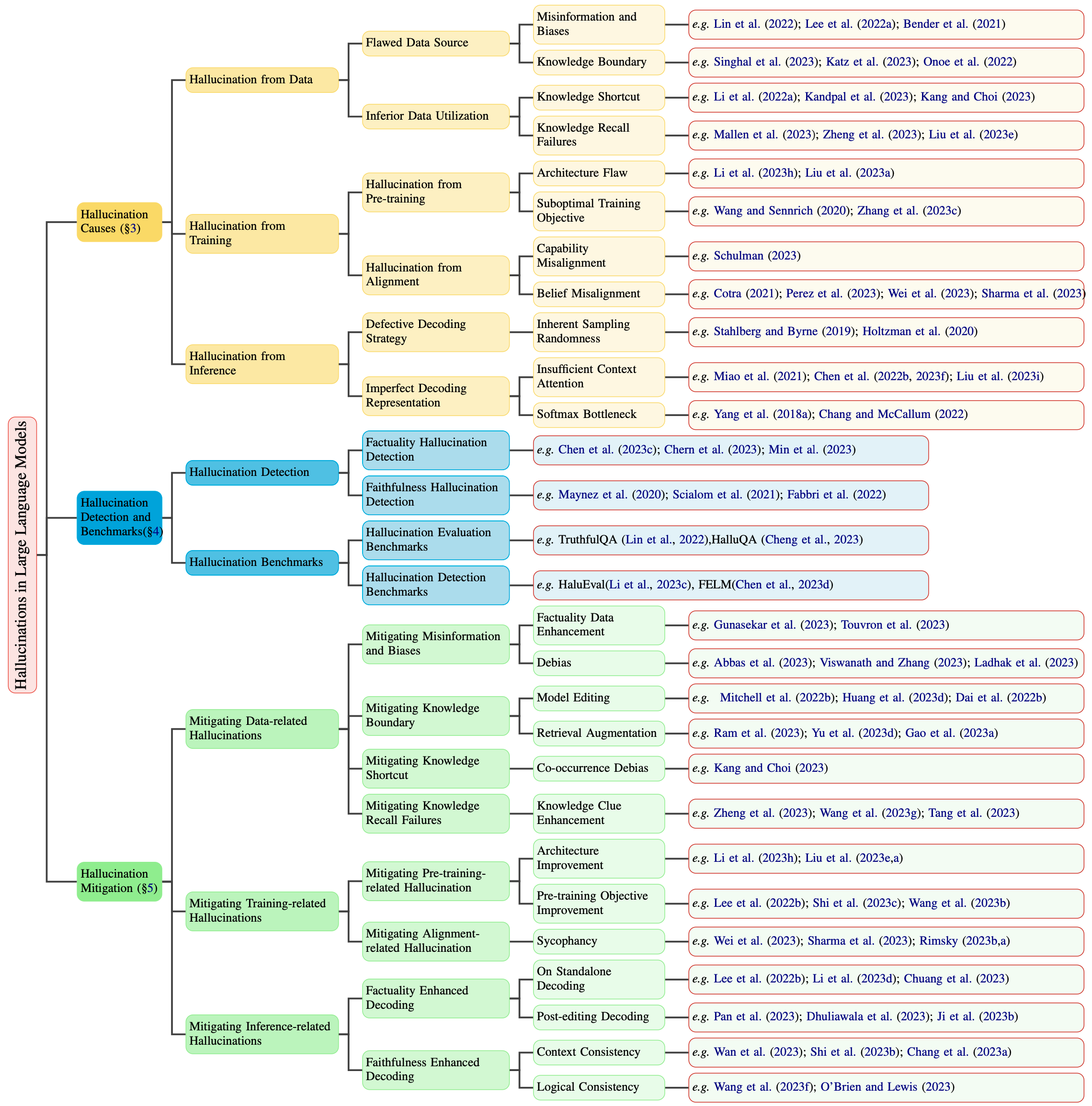
Another interesting paper you should read is: Cognitive Mirage: A Review of Hallucinations in LLMs.
Detecting and measuring AI hallucinations. Since there are so many types of hallucinations and some of then are quite subtle, there is a need for tools and methods to measure and evaluate hallucinations properly.
Checkout this great repo with lots of resources and papers on Awesome Hallucination Detection.
A few days ago, an AI startup called Vectara, just open-sourced Hallucination Evaluation Model (HEM), a tool that provides a FICO-like score for grading how often a generative LLM hallucinates in Retrieval Augmented Generation (RAG) systems. Read mode in this blogpost: Measuring Hallucinations in RAG Systems
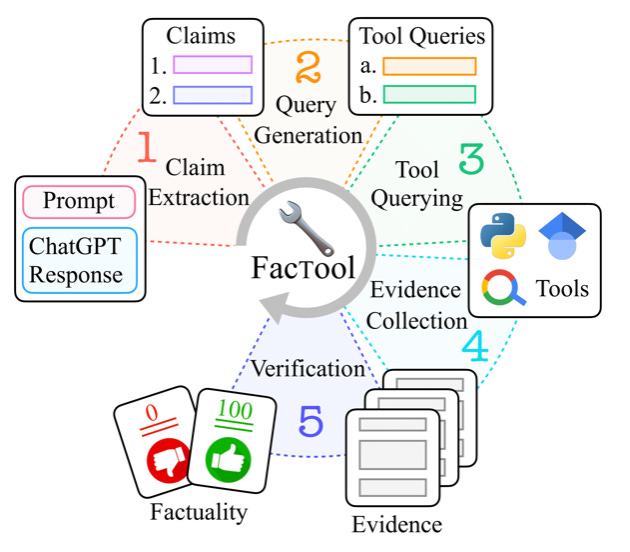
Factool, is another interesting tool augmented framework for detecting factual errors of texts generated by LLMs. Factool supports 4 tasks: knowledge-based QA, code generation, mathematical reasoning, and scientific literature review. Checkout project website, paper, and repo: FacTool: Factuality Detection in Generative AI.
Giskard is a fantastic open-source tool for detecting a wide range of LLM vulnerabilities, from performance biases and data leakage to more nuanced issues like spurious correlations, hallucination, and even toxicity. Checkout this tutorial on how to use Giskard for evaluating bias, hallucinations and more in RAG.
Mitigating AI hallucinations. Mitigating hallucinations is tricky. It requires a lot of experimentation, iterations… As I wrote above, there are many techniques to mitigate or minimise hallucinations, but some of these techniques are not 100% reliable and require a lot effort and time. Here are some new techniques to mitigate hallucinations:
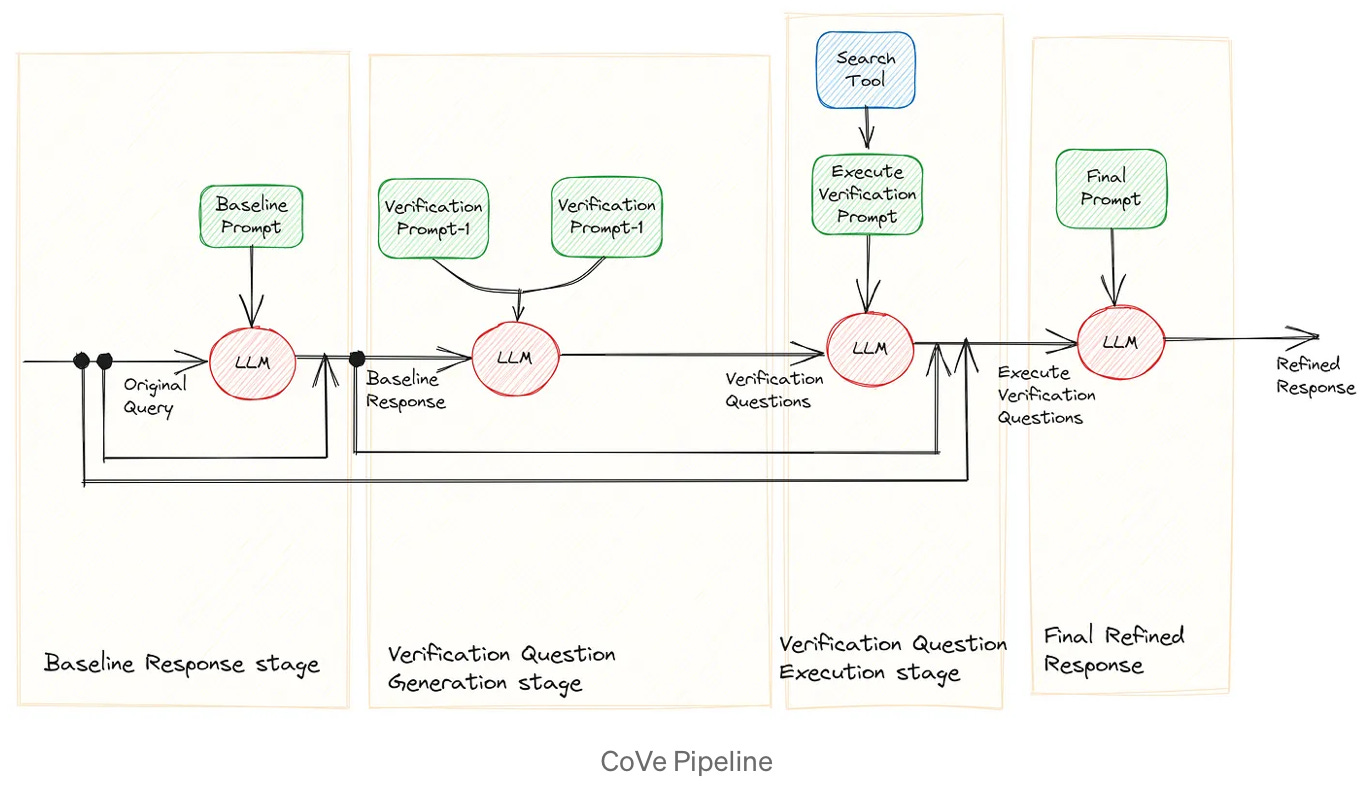
Chain of Verification (CoVe) is a method to reduce hallucinations based in the notion that a response generated by a LLM can be used to validate itself. This self-verification process is employed to assess the accuracy of the initial response and refine it for greater precision. Achieving this relies on skillfully crafting and sequencing LLM prompts. This is a great blog post on Understanding and Implementing Chain of Verification.
Forward-looking Active RAG (FLARE) is a generic method that can be used to minimise hallucinations. This method iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilised as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens. In this blogpost, Anthony summarises the FLARE paper: Improving Language Models Through Active Information Retrieval (FLARE.)
CoBa (Correction with Backtracking), a new method presented by Deepmind & Cornell Uni researchers, to reduce hallucination in abstractive summarisation. This method is based on two steps: hallucination detection and mitigation. The researchers show that the former can be achieved through measuring simple statistics about conditional word probabilities and distance to context words. The researchers claim CoBa is surprisingly effective and efficient in reducing hallucination, and offers great adaptability and flexibility.
Just a few days ago, UC Berkeley et. al introduced SynTra, a new method that uses synthetic tasks where hallucinations are easy to elicit and measure. It next optimizes the LLM's system message via prefix-tuning on the synthetic task, and finally transfers the system message to realistic, hard-to-optimize tasks. Paper: Teaching Language Models to Hallucinate Less with Synthetic Tasks.
Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
SPHINX: A Multi-Model Mixer of Tasks, Domains, and Embeddings
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.