




Discover more from Data Machina
Data Machina #235
Advanced RAG. RAGatouille + ColBERT 2. Transformers Math. Mixtral-8x7b MoEs Explained. YALE Math & Code Models. SQL AI Agents? OpenVoice. mergekit. Apple MLX Deep Dive. LASER Reasoning. GEO GenAI SEO
RAG to AI Riches: How to improve your naive RAG app. OK, so you’ve been FAFOing with RAG PoCs and protos during six months… You’ve realised the hard way that your naive/ dumb RAG app won’t ever deliver the results that your business is truly expecting in live production… Now what? Here are several tips and notes on building Advanced RAG apps.
A reliable, robust RAG system in prod is really complex. So many moving parts in a RAG pipeline! Typical Qs you need to answer: What’s the best chunking strategy? Which embedding model is best? How, when and what to retrieve? Which retriever to use? How to get top ranked, relevant results? How to mitigate hallucinations? How to optimise RAG performance, latency, and cost at the same time? … and so on.
Start here: Deeply understand all the aspects of RAG fully. IMO, this is by far the most awesome survey paper on RAG. From dumb to advanced and modular RAG, this paper is loaded with key insights on RAG. A must read: RAG for LLMs: A Survey v3 (January 2024). Also do checkout the excellent, accompanying presentation on RAG: Paradigms, Technologies, and Trends.
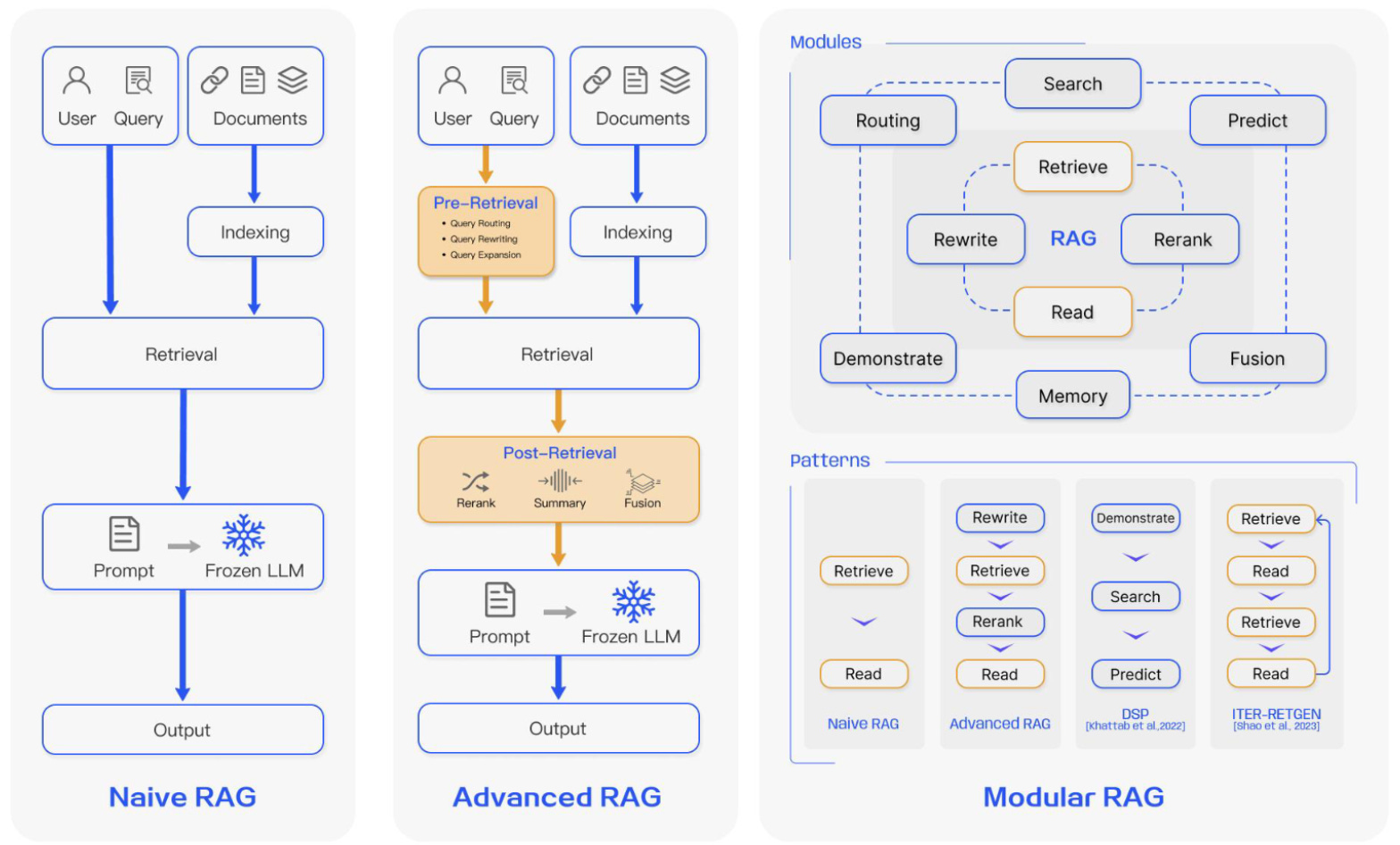
Get inspiration, recipes on building advanced RAG. If you've built a basic/naive RAG system and are now looking to enhance it to something more advanced, this blogpost provides some nice recipes to build advanced RAG apps. Blogpost: A Cheat Sheet and Some Recipes For Building Advanced RAG.
Learn more on RAG advanced techniques. This is a comprehensive post on advanced RAG techniques and algos. The blogpost comes with a collection of links referencing various implementations and research mentioned. Blogpost: Advanced RAG Techniques: an Illustrated Overview.
Implement new methods to avoid hallucinations in RAG answers. This new paper presents a comprehensive survey of over 32 techniques developed to mitigate hallucination in LLMs. The paper introduces a detailed taxonomy categorising hallucination-avoidance methods based on various parameters. Paper: A Comprehensive Survey of Hallucination Mitigation Techniques in LLMs.
Learn how to improve RAG queries and prompting. This paper introduces 26 guiding principles for optimising queries and prompting. Checkout the repo and paper here: Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4.
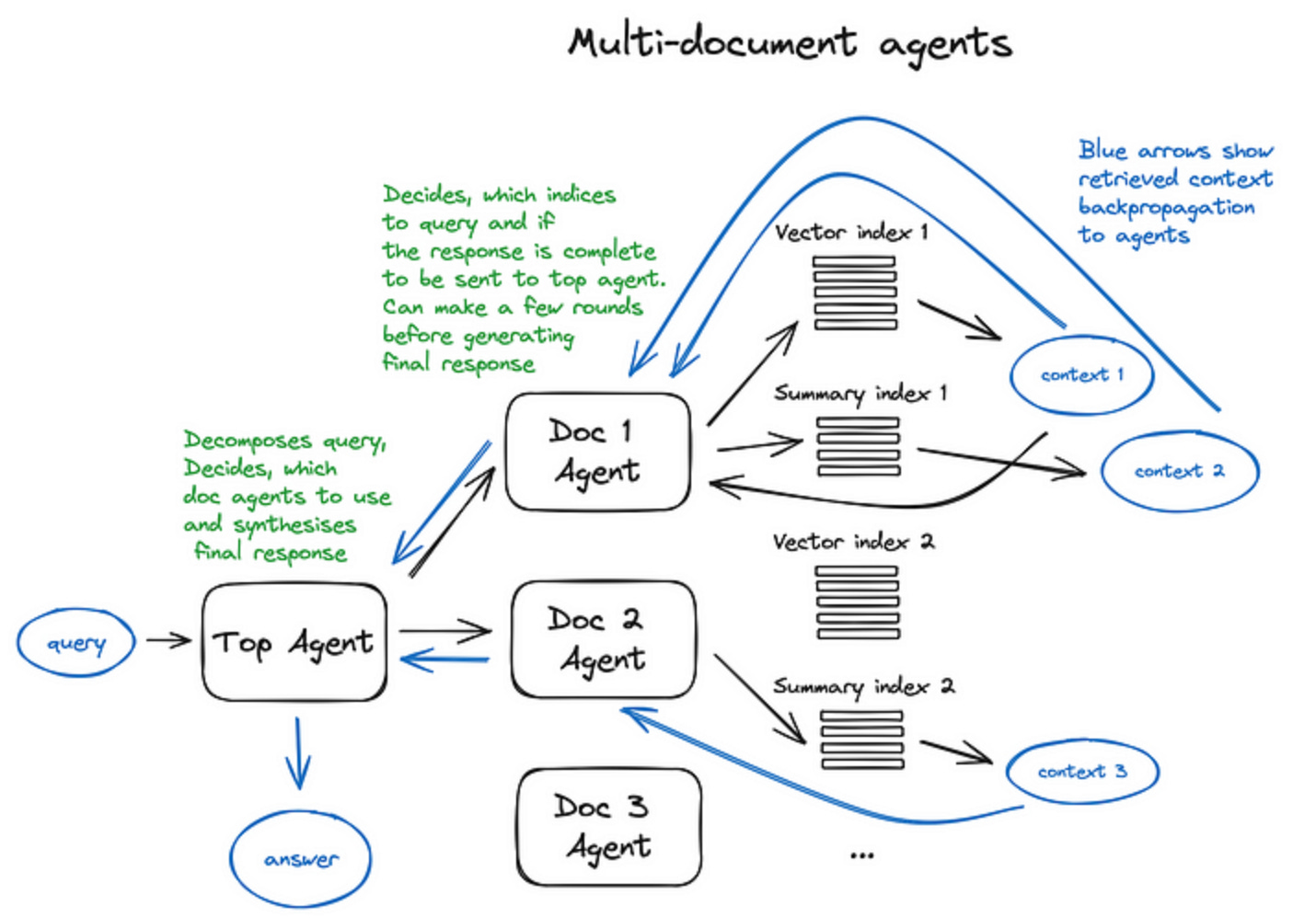
Improve RAG answers by adding agents. Adding agents to your RAG pipeline can allow your RAG to reason over much more complex questions. But a big pain point for agents is the lack of steerability /transparency. This notebook shows you how to use and control LLamaindex agents in RAG pipelines. Notebook: Controllable Agents for RAG.
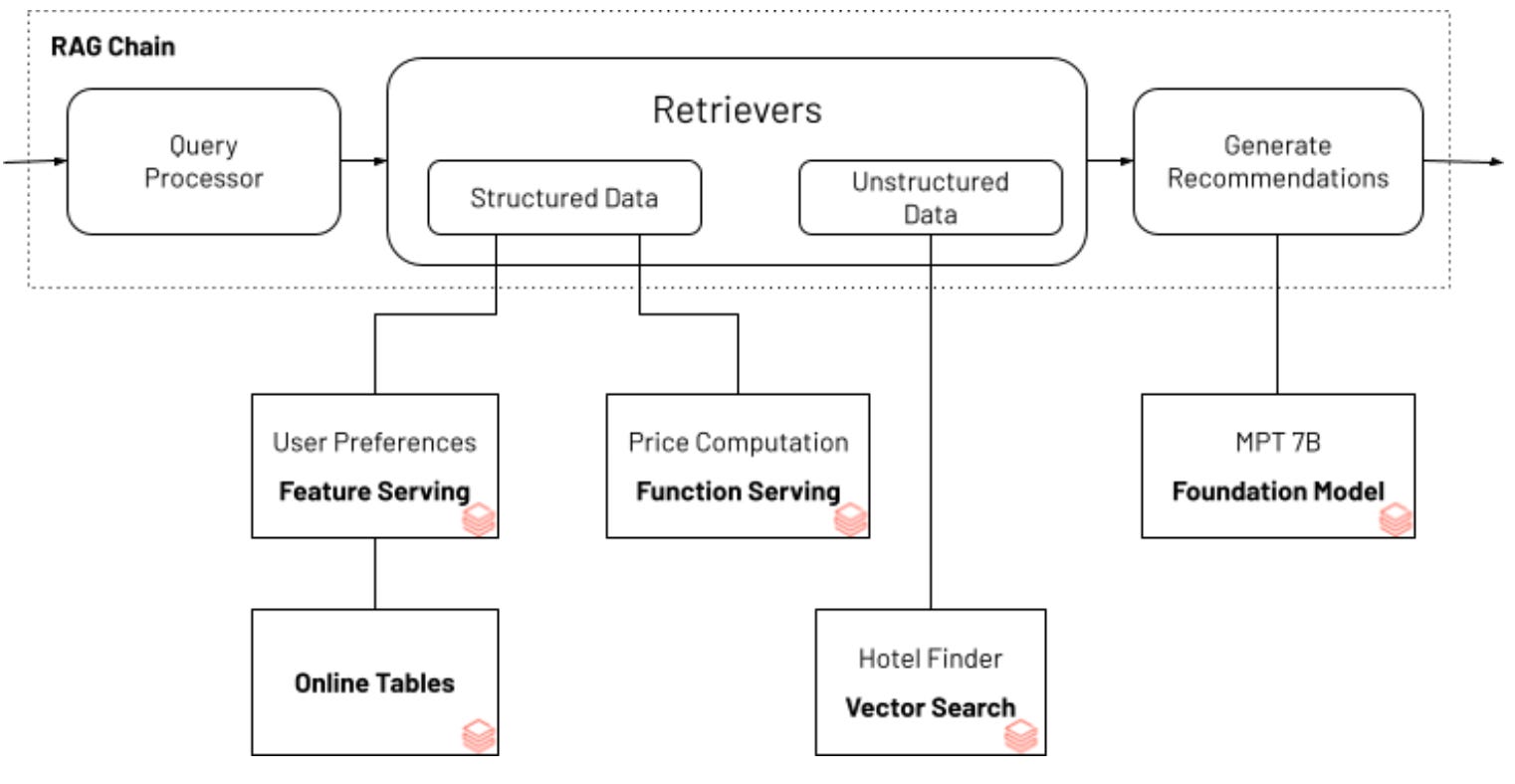
Improve RAG performance using structured-data. A nice blogpost from the DataBricks team on how to improve RAG performance using Databricks Feature & Function Serving, a low latency real-time service designed to serve structured data. Blogpost: Improve your RAG app response quality with real-time structured data.
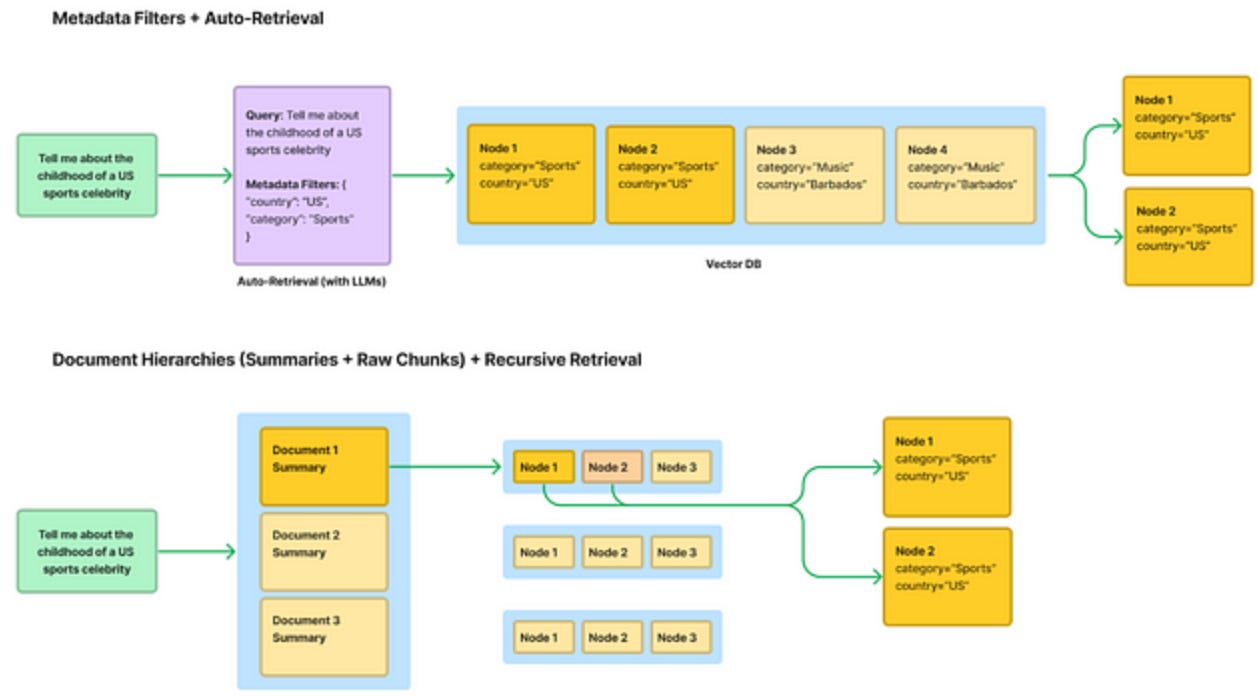
Optimise RAG production performance. This is a cool guide that provides insights, strategies, to enhance the efficiency of your RAG pipeline, catering to complex datasets and ensuring accurate query responses without hallucinations. Blogpost: Optimizing RAG Systems with LlamaIndex: Strategies for Production Performance.
Add multi-modality to your RAG pipeline. The emergence of multi-modal open source models like LLaVa, and Fuyu-8B is a powerful trend. Just checkout Awesome Multi-modal Models. Multi-modality can enable more powerful RAG apps. This is a great blogpost on how you can implement Multi-modal RAG.
New approach: Use fast, accurate SOTA retrievers in your RAG Pipeline. A key component that determines the quality of RAG is the retriever model. Recent research shows that dense retrieval models that use e.g. embeddings like OpenAI's text-ada-002, may not deliver top results in certain domains. New research indicates that alternative retrieval models like Standford ColBERT v2 generalise better to new or complex domains than dense retrievers. And also are super data-efficient and are even better suited to efficiently being trained with low amount of data! Welcome to RAGatouille: Easily use and train SOTA effective retrieval models in your RAG pipeline. RAGatouille is really a big deal, and it’s revolutionising RAG apps development!
Combine Mixture-of-Experts models with RAG. Mixture-of-Experts models are all the rage now. This article will show you how to use LlamaIndex, Jina Embeddings, and the Mixtral-8x7B MoEs model to build a complete RAG system. Blogpost: Full-stack RAG with Jina Embeddings v2, LlamaIndex & Mixtral-8x7B.
Leverage this new SOTA embeddings model in your RAG. MS Research just published a novel and simple method for obtaining SOTA text embeddings using only synthetic data and less than 1k training steps. Paper: Improving Text Embeddings with LLMs and Synthetic Data.
Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
data v-i-s-i-o-n-s
MLOps Untangled
AI startups -> radar
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Subscribe to Data Machina
A weekly deep dive into the latest AI / ML research, projects & repos.








