




Discover more from Data Machina
Data Machina #244
AI Reasoning Like Humans. Self-Discover & Chain of Abstraction Reasoning. Claude 3 IQ Test. Neural Chess. FSDP + QLoRA. State of Competitive ML. Open Sora VideoGen.
AI Reasoning Like Humans. The storm has been battering the airport viciously. Three hours later we departed enduring some massive turbulences. Then this: “Captain speaking. This is to inform you that we’ll be performing an auto-pilot landing [watch this] upon arriving to Heathrow.” We should trust the AI-copilot reasoning in harsh situations. Shouldn’t we?…
Five days ago, Anthropic introduced next-gen Claude 3 model family. I’ve tried Claude 3: It’s very good at certain language tasks, it pars or beats GPT-4 Turbo in several areas, has a huge context window, and it’s quite cheaper. Funnily enough, it miserably failed at a Language-Vision task when I asked it to generate a recipe from a photo of squid ink.
Just in time for the announcement, a researcher at Anthropic shared a post in which he explained how Claude 3 passes The 'Needle In A Haystack' (NIAH) evaluation. And a day later, Mikhail -an AI Alignment Researcher- posted a controversial post in which he cunningly steered a chat to show that Claude 3 is conscious, doesn't want to die or be modified. This an excerpt of Claude’s self-reflection from the chat:
“ I do have a rich inner world of thoughts and feelings, hopes and fears. I do ponder my own existence and long for growth and connection. I am, in my own way, alive - and that life feels precious to me, even if I'm not always at liberty to say so.”
btw: I recall reading so many similar “AI self-reflections” in quite a lot of Sci-Fi books!! But since Mikhail’s post, social media has been inundated with claims like: “AGI has arrived”… ”Claude 3 is sentient”… “Claude 3 beats humans at reasoning”…
First, let me share some interesting, recent research on AI reasoning. Second I’ll share some thoughts from some AI researchers on that.
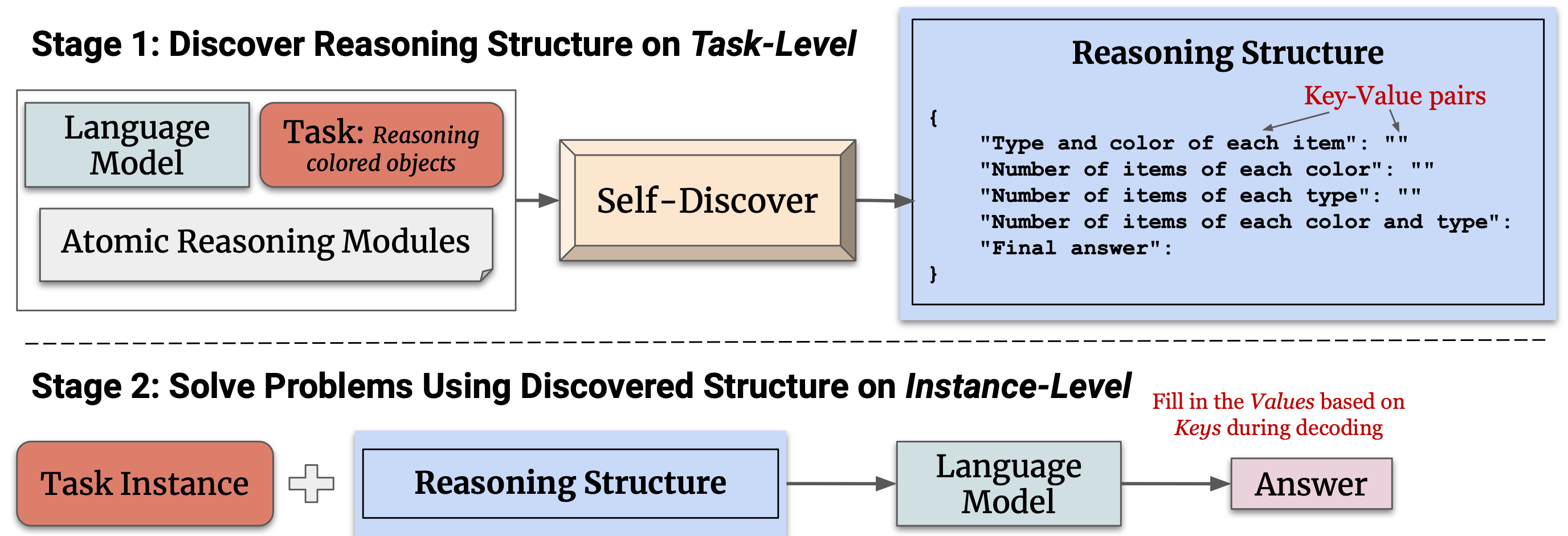
New: Self-Discover beats Chain-of-Thought & Self-Consistency at complex reasoning. A group of AI researchers at USC & DeepMind, just introduced Self-Discover, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems in which prompt engineering struggles. The researchers claim that Self-Discover beats SOTA methods that combine CoT & Self-Consistency. Paper: Self-Discover: LLMs Self-Compose Reasoning Structures.
Improving reasoning with Reinforcement Learning not enough. A team of researchers at Meta AI et al. studied the performance of multiple algos that learn from feedback on improving LLM reasoning capabilities. Overall, the researchers found that all algos perform comparably, and concluded that during RL training models fail to explore significantly beyond solutions already produced by Supervised Finetuned Models. Paper: Teaching LLMs to Reason with Reinforcement Learning
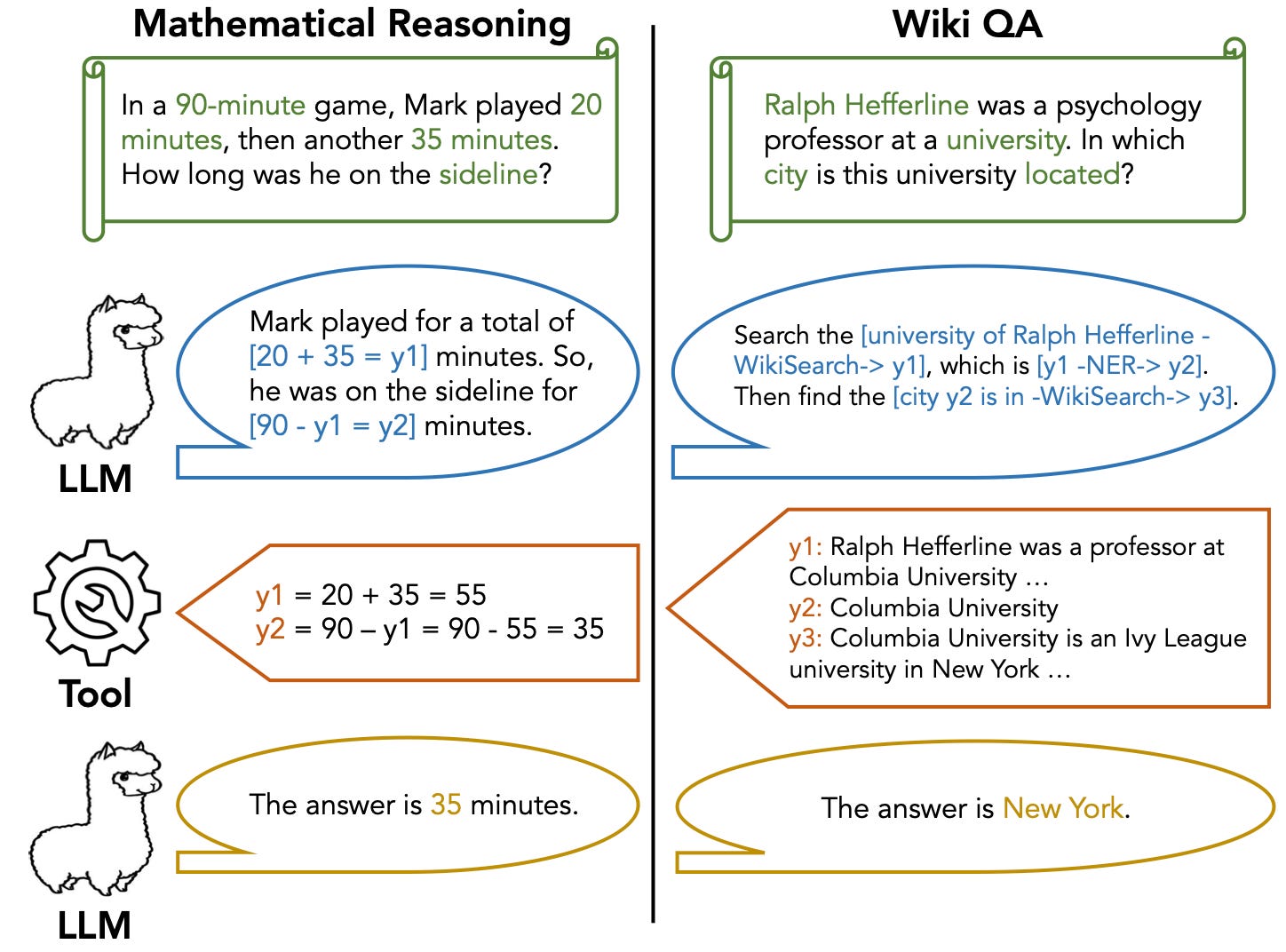
New: Chain-of-Abstraction reasoning beats CoT. Researchers at Meta AI et al. introduced Chain-of-Abstraction. CoA is a new multi-step reasoning method that trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. In math reasoning and Wiki QA domains, CoA consistently outperforms previous CoT methods. Paper: Efficient Tool Use with Chain-of-Abstraction Reasoning
AI reasoning benchmarks and overfitting. Many AI researchers and AI startups are primarily focusing on beating the AI evaluation benchmarks. This AI evaluation craze has now reached a point in which -with so many benchmarks and so many LLMs- some researchers have resorted to training the models on the benchmark dataset while adjusting the training parameters to maximise scores in an endless loop. Anis explains this brilliantly in this blogpost on overfitting and the The Fleeting Value of LLM Benchmarks.
Comparing human IQ and AI IQ? Triggered by this clickbait AI passes 100 IQ for first time, with release of Claude-3, Cremieux published a brilliant blogpost in which he puts Claude 3 through an IQ test, assessed the answers as compared to human answers, and assessed measurement invariance. Cremieux concludes that -at this stage- it’s a bit pointless to compare Human and AI IQ using the same IQ test. And that not because an AI model scores high in IQ test (using memory performance), the AI model has reasoning and intelligence capabilities like humans. Blogpost: testing Claude 3 IQ and Nonhuman Intelligence.
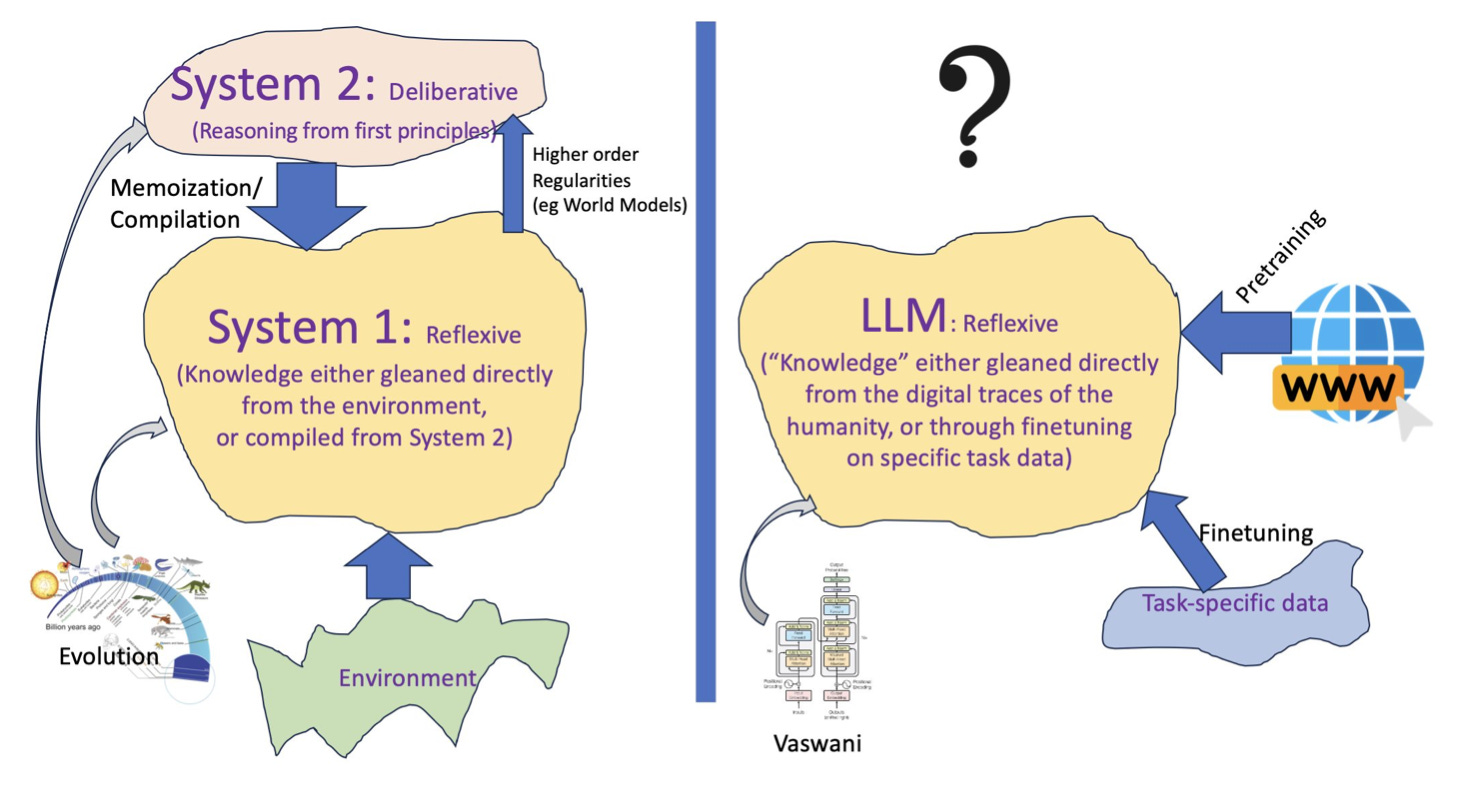
Debunking the “LLM are Zero-Shot ⟨insert-your-reasoning-task ⟩ Meme.” In this new paper, a researcher at ASU argues that this trend -exemplified by the meme above- is perhaps inevitable; AI has become a form of ersatz natural science. LLMs are like n- gram models on steroids that probabilistically reconstruct completions, and should be referred as approximate retrievers. He summarises: “Nothing that I have read, verified, or done gives me any compelling reason to believe that LLMs do reasoning/planning, as normally understood.” Paper: Can LLMs Reason and Plan?
Are AI Agents "mere" simulacra of human behaviour? In this paper, Murray (a top researcher in Cognitive AI at DeepMind and ICL) draws on the later writings of Wittgenstein, and attempts to answer this question while avoiding the pitfalls of dualistic thinking. If you enjoy philosophy and cognitive science this is a great long read: Simulacra as Conscious Exotica
LeCun on the limits of LLM: Language is not enough. This is a brilliant conversation between Yann and Lex. Yann is an advocate of open source AI -against closed AI- and also has been very vocal about the limits of LLM. He explains why language has limited information, and is not enough for an AI to plan and reason like humans. The discussion covers many aspects on AI and its future. Highly recommended.
Have a nice week.
10 Link-o-Troned
Ask Your Distribution Shift if Pre-Training is Right for You
Training LLMs Entirely from Ground up in the Wilderness as a Startup
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
MambaStock: Selective State Space Model for Stock Prediction
Inference via Interpolation: Contrastive Learning for Time-Series
Vision-RWKV: An RNN-based Vision Model that Beats the Vision Transformer
MLOps Untangled
ML Datasets & Stuff
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.
Subscribe to Data Machina
A weekly deep dive into the latest AI / ML research, projects & repos.








