
Data Machina #251
Three New Powerful Open AI Models. Snowflake Artic. Apple OpenELM. Microsoft Phi-3. OpenVoicev2.Open-Sora. JAT Agent. GTE SOTA Embeddings. Maestro Subagents. Cohere RAG Toolkit. Diffusion GenAI Video.
Three New Powerful Open AI Models. I’m told by colleagues at Hugging Face that just a week since LLama-3 was released, more than +10,000 model derivatives have been developed! The pressure on black-box, closed AI models is huge, and achieving GPT-4 performance with open, smallish models is upon us. Which is great.
In the last few days, three new, smallish, powerful open AI models were released. Interestingly enough, the power of these 3 models is based on a combination of: 1) Innovative training architectures and optimisation techniques, and 2) Data quality for different types of data (synthetic, public or private). Let’s see…
Snowflake Artic 17B: A new, truly open source (Apache 2.0) model that has been modelled for enterprise intelligence. Snowflake Artic 17B is based on a Dense - MoE Hybrid Transformer architecture. It outperforms all other open models in three areas that are the most demanded in enterprise AI : 1) conversational SQL (Text-to-SQL), 2) coding copilots and 3) RAG chatbots. The model is also supper efficient in terms of training and low cost, two things much valued in enterprise too. Checkout the official blogpost: Snowflake Arctic: The Best LLM for Enterprise AI — Efficiently Intelligent, Truly Open.
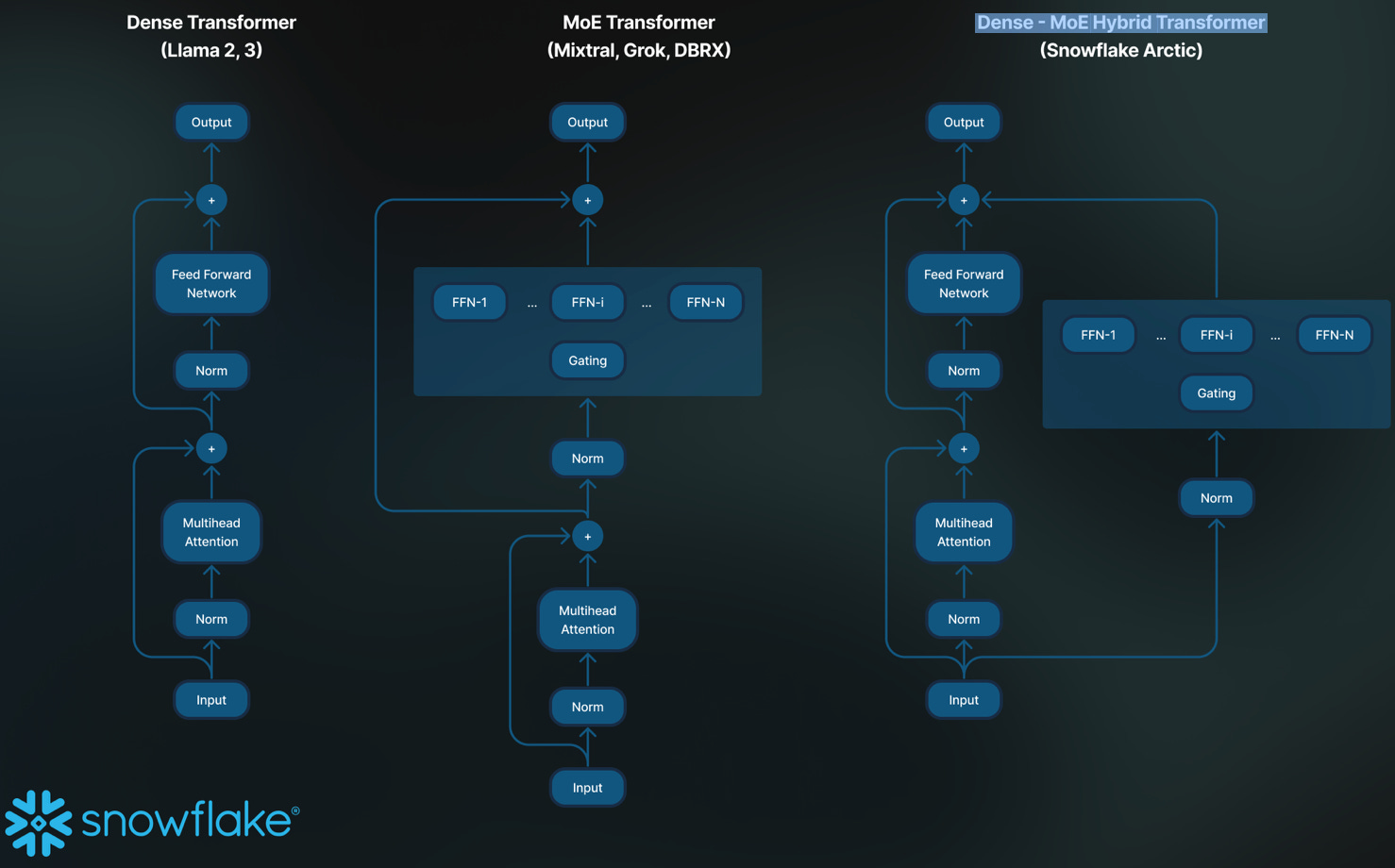
The release of Snowflake Artic 17B also comes with a Cookbook series starting with:
Building an Efficient Training System for Arctic A review on how the DeepSpeed library was used to optimise efficient large MoE training using several optimisation techniques like ZeRO-2 and expert-parallelism.
Exploring Mixture of Experts (MoE) A review on why and how the Snowflake AI team decided to develop and train a model with a Dense-MoE Hybrid Architecture.
You can try and run Snowflake-arctic-instruct on Replicate and Streamlit
Apple OpenELM. OpenELM, a new family of eight SOTA open language models. The model has been released in both pretrained and instruction tuned versions with 270M, 450M, 1.1B and 3B parameters. You can get the OpenELM models card and model versions in HugginFace.
OpenELM was inspired by Allen AI OLMo, which is one of most performant, truly open models. OpenELM outperforms OLMo by using an innovative layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, which enhances accuracy in a more efficient way, using 2× fewer pre-training tokens. The original paper is an excellent read: OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
OpenELM was developed using the new Apple CoreNet library. You can run OpenELM quantised models in your MacBook using Apple MLX framework. Also checkout this iPynb to run an OpenELM 3B demo on Gradio.
Microsoft Phi-3. This is a new family of open AI models developed by Microsoft. Microsoft claims that the Phi-3 models are the most capable and cost-effective small language models (SLMs).
Here is the official blogpost with the technical report, model card and deployable environments on Microsoft Azure AI Studio, Hugging Face, and Ollama: Introducing Phi-3: Redefining what’s possible with SLMs
The innovation here perhaps is the way specific data training was used to achieve such high performance in such a small model which also comes with a big 128K context window size. You can expect Phi-3 running on smart phone devices an delivering great output.
Check-out the powerful Phi-3-Mini-128K-Instruct version, a 3.8B model that uses the Phi-3 datasets. Also sees this great post on How to Finetune phi-3 on MacBook Pro.
OpenVoice v2. Although not exactly a “new” model, I added this as a fourth bonus model :-) as I think it’s worth mentioning an important update. The very latest April v2 comes with 1) Free commercial use MIT license, 2) Native multi-lingual support in English, Spanish, French, Chinese, Japanese and Korean, and 3) Much better audio quality due to new audio data training strategy. Checkout the original paper, demos and repo here: OpenVoice: Versatile Instant Voice Cloning.
Have a nice week.
10 Link-o-Troned
the ML Pythonista
Deep & Other Learning Bits
AI/ DL ResearchDocs
MLOps Untangled
ML Datasets & Stuff
[!!] HuggingFace FineWeb: 15 Trillion Tokens of the Finest Web Data
UTD19 - The Largest, Public Traffic Dataset, 40 Cities, 170M Rows
3LC - An AI Tool That Lets You See Your Dataset Through Your Model’s Eyes
Postscript, etc
Tips? Suggestions? Feedback? email Carlos
Curated by @ds_ldn in the middle of the night.